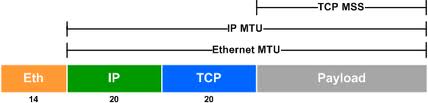
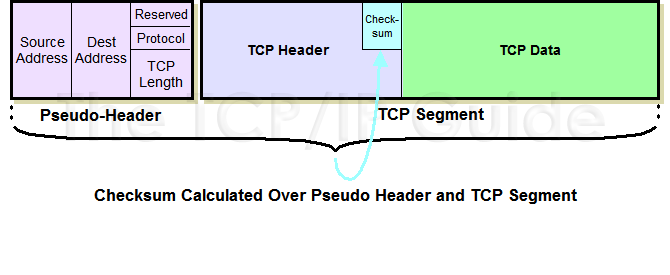
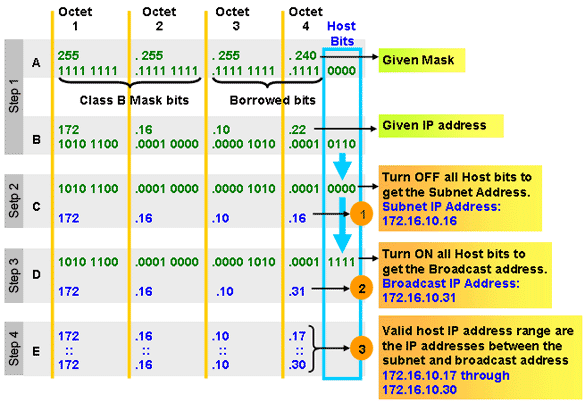
OSI Model Physical Layer
The physical layer defines the electrical, mechanical, procedural, and functional specifications for activating, maintaining, and deactivating the physical link between communicating network systems. Physical layer specifications define characteristics such as voltage levels, the timing of voltage changes, physical data rates, maximum transmission distances, and physical connectors. Physical layer implementations can be categorized as either LAN or WAN specifications.
Figure: Physical Layer Implementations Can Be LAN or WAN Specifications
OSI Model Data Link Layer
The data link layer provides reliable transit of data across a physical network link. Different data link layer specifications define different network and protocol characteristics, including physical addressing, network topology, error notification, sequencing of frames, and flow control. Physical addressing (as opposed to network addressing) defines how devices are addressed at the data link layer. Network topology consists of the data link layer specifications that often define how devices are to be physically connected, such as in a bus or a ring topology. Error notification alerts upper-layer protocols that a transmission error has occurred, and the sequencing of data frames reorders frames that are transmitted out of sequence. Finally, flow control moderates the transmission of data so that the receiving device is not overwhelmed with more traffic than it can handle at one time.
The Institute of Electrical and Electronics Engineers (IEEE) has subdivided the data link layer into two sublayers: Logical Link Control (LLC) and Media Access Control (MAC).
Figure: The Data Link Layer Contains Two Sublayers
The Logical Link Control (LLC) sublayer of the data link layer manages communications between devices over a single link of a network. LLC is defined in the IEEE 802.2 specification and supports both connectionless and connection-oriented services used by higher-layer protocols. IEEE 802.2 defines some fields in data link layer frames that enable multiple higher-layer protocols to share a single physical data link. The Media Access Control (MAC) sublayer of the data link layer manages protocol access to the physical network medium. The IEEE MAC specification defines MAC addresses, which enable multiple devices to uniquely identify one another at the data link layer.
Examples of data link protocols are Ethernet for local area networks (multi-node), the Point-to-Point Protocol (PPP), HDLC and ADCCP for point-to-point (dual-node) connections.
OSI Model Network Layer
The network layer defines the network address, which differs from the MAC address. Some network layer implementations, such as the Internet Protocol (IP), define network addresses in a way that route selection can be determined systematically by comparing the source network address with the destination network address and applying the subnet mask. Because this layer defines the logical network layout, routers can use this layer to determine how to forward packets. Because of this, much of the design and configuration work for internetworks happens at Layer 3, the network layer.
OSI Model Transport Layer
The transport layer accepts data from the session layer and segments the data for transport across the network. Generally, the transport layer is responsible for making sure that the data is delivered error-free and in the proper sequence. Flow control occurs typically at the transport layer.
Flow control manages data transmission between devices so that the transmitting device does not send more data than the receiving device can process. Multiplexing enables data from several applications to be transmitted onto a single physical link. Virtual circuits are established, maintained, and terminated by the transport layer. Error checking involves creating various mechanisms for detecting transmission errors, while error recovery involves acting, such as requesting that data be retransmitted, to resolve any errors that occur.
The transport protocols used on the Internet are TCP and UDP.
OSI Model Session Layer
The session layer establishes, manages, and terminates communication sessions. Communication sessions consist of service requests and service responses that occur between applications located in different network devices. These requests and responses are coordinated by protocols implemented at the session layer. Some examples of session-layer implementations include Zone Information Protocol (ZIP), the AppleTalk protocol that coordinates the name binding process; and Session Control Protocol (SCP), the DECnet Phase IV session layer protocol.
OSI Model Presentation Layer
The presentation layer provides a variety of coding and conversion functions that are applied to application layer data. These functions ensure that information sent from the application layer of one system would be readable by the application layer of another system. Some examples of presentation layer coding and conversion schemes include common data representation formats, conversion of character representation formats, common data compression schemes, and common data encryption schemes.
Common data representation formats, or the use of a standard image, sound, and video formats, enable the interchange of application data between different types of computer systems. Conversion schemes are used to exchange information with systems by using different text and data representations, such as EBCDIC and ASCII. Standard data compression schemes enable data that is compressed at the source device to be properly decompressed at the destination. Standard data encryption schemes enable data encrypted at the source device to be properly deciphered at the destination.
Presentation layer implementations are not typically associated with a particular protocol stack. Some well-known standards for video include QuickTime and Motion Picture Experts Group (MPEG). QuickTime is an Apple Computer specification for video and audio, and MPEG is a standard for video compression and coding.
Among the well-known graphic image formats are Graphics Interchange Format (GIF), Joint Photographic Experts Group (JPEG), and Tagged Image File Format (TIFF). GIF is a standard for compressing and coding graphic images. JPEG is another compression and coding standard for graphic images, and TIFF is a standard coding format for graphic images.
OSI Model Application Layer
The application layer is the OSI layer closest to the end user, which means that both the OSI application layer and the user interact directly with the software application.
This layer interacts with software applications that implement a communicating component. Such application programs fall outside the scope of the OSI model. Application layer functions typically include identifying communication partners, determining resource availability, and synchronizing communication.
When identifying communication partners, the application layer determines the identity and availability of communication partners for an application with data to transmit. When determining resource availability, the application layer must decide whether sufficient network resources for the requested communication exist. In synchronizing communication, all communication between applications requires cooperation that is managed by the application layer.
Some examples of application layer implementations include Telnet, File Transfer Protocol (FTP), and Simple Mail Transfer Protocol (SMTP).
OSI, TCP/IP and Encapsulation
C. Describe the purpose of the various address types at different OSI layers.
Internetwork Addressing
Internetwork addresses identify devices separately or as members of a group. Addressing schemes vary depending on the protocol family and the OSI layer. Three types of internetwork addresses are commonly used: data link layer addresses, Media Access Control (MAC) addresses, and network layer addresses.
Data Link Layer Addresses
A data link layer address uniquely identifies each physical network connection of a network device. Data-link addresses sometimes are referred to as physical or hardware addresses. Data-link addresses usually exist within a flat address space and have a pre-established and typically fixed relationship to a specific device.
End systems generally have only one physical network connection and thus have only one data-link address. Routers and other internetworking devices typically have multiple physical network connections and therefore have multiple data-link addresses.
Figure: Each Interface on a Device Is Uniquely Identified by a Data-Link Address
MAC Addresses
Media Access Control (MAC) addresses consist of a subset of data link layer addresses. MAC addresses identify network entities in LANs that implement the IEEE MAC addresses of the data link layer. As with most data-link addresses, MAC addresses are unique for each LAN interface.
Figure: MAC Addresses, Data-Link Addresses, and the IEEE Sublayers of the Data Link Layer Are All Related
MAC addresses are 48 bits in length and are expressed as 12 hexadecimal digits. The first 6 hexadecimal digits, which are administered by the IEEE, identify the manufacturer or vendor and thus comprise the Organizationally Unique Identifier (OUI). The last 6 hexadecimal digits comprise the interface serial number or another value administered by the specific vendor. MAC addresses sometimes are called burned-in addresses (BIAs) because they are burned into read-only memory (ROM) and are copied into random-access memory (RAM) when the interface card initializes.
Figure: The MAC Address Contains a Unique Format of Hexadecimal Digits
Mapping Addresses
Because internetworks generally use network addresses to route traffic around the network, there is a need to map network addresses to MAC addresses. When the network layer has determined the destination station’s network address, it must forward the information over a physical network using a MAC address. Different protocol suites use different methods to perform this mapping, but the most popular is Address Resolution Protocol (ARP).
Different protocol suites use different methods for determining the MAC address of a device. The following three methods are used most often. Address Resolution Protocol (ARP) maps network addresses to MAC addresses. The Hello protocol enables network devices to learn the MAC addresses of other network devices. MAC addresses either are embedded in the network layer address or are generated by an algorithm.
Address Resolution Protocol (ARP) is the method used in the TCP/IP suite. When a network device needs to send data to another device on the same network, it knows the source and destination network addresses for the data transfer. It must somehow map the destination address to a MAC address before forwarding the data. First, the sending station will check its ARP table to see if it has already discovered this destination station’s MAC address. If it has not, it will send a broadcast on the network with the destination station’s IP address contained in the broadcast. Every station on the network receives the broadcast and compares the embedded IP address to its own. Only the station with the matching IP address replies to the sending station with a packet containing the MAC address for the station. The first station then adds this information to its ARP table for future reference and proceeds to transfer the data.
When the destination device lies on a remote network, one beyond a router, the process is the same except that the sending station sends the ARP request for the MAC address of its default gateway. It then forwards the information to that device. The default gateway will then forward the information over whatever networks necessary to deliver the packet to the network on which the destination device resides. The router on the destination device’s network then uses ARP to obtain the MAC of the actual destination device and delivers the packet.
The Hello protocol is a network layer protocol that enables network devices to identify one another and indicate that they are still functional. When a new end system powers up, for example, it broadcasts hello messages onto the network. Devices on the network then return hello replies, and hello messages are also sent at specific intervals to indicate that they are still functional. Network devices can learn the MAC addresses of other devices by examining Hello protocol packets.
Three protocols use predictable MAC addresses. In these protocol suites, MAC addresses are predictable because the network layer either embeds the MAC address in the network layer address or uses an algorithm to determine the MAC address. The three protocols are Xerox Network Systems (XNS), Novell Internetwork Packet Exchange (IPX), and DECnet Phase IV.
Network Layer Addresses
A network layer address identifies an entity at the network layer of the OSI layers. Network addresses usually exist within a hierarchical address space and sometimes are called virtual or logical addresses.
The relationship between a network address and a device is logical and unfixed; it typically is based either on physical network characteristics (the device is on a particular network segment) or on groupings that have no physical basis (the device is part of an AppleTalk zone). End systems require one network layer address for each network layer protocol that they support. (This assumes that the device has only one physical network connection.) Routers and other internetworking devices require one network layer address per physical network connection for each network layer protocol supported. For example, a router with three interfaces each running AppleTalk, TCP/IP, and OSI must have three network layer addresses for each interface. The router, therefore, has nine network layer addresses.
Figure: Each Network Interface Must Be Assigned a Network Address for Each Protocol Supported
Hierarchical Versus Flat Address Space
Internetwork address space typically takes one of two forms: hierarchical address space or flat address space. A hierarchical address space is organized into numerous subgroups, each successively narrowing an address until it points to a single device (in a manner similar to street addresses). A flat address space is organized into a single group (in a manner similar to U.S. Social Security numbers).
Hierarchical addressing offers certain advantages over flat-addressing schemes. Address sorting and recall is simplified using comparison operations. For example, “Ireland” in a street address eliminates any other country as a possible location.
Figure: Hierarchical and Flat Address Spaces Differ in Comparison Operations
Address Assignments
Addresses are assigned to devices as one of two types: static and dynamic. Static addresses are assigned by a network administrator according to a preconceived internetwork addressing plan. A static address does not change until the network administrator manually changes it. Dynamic addresses are obtained by devices when they attach to a network, using some protocol-specific process. A device using a dynamic address often has a different address each time that it connects to the network. Some networks use a server to assign addresses. Server-assigned addresses are recycled for reuse as devices disconnect. A device is therefore likely to have a different address each time that it connects to the network.
Addresses Versus Names
Internetwork devices usually have both a name and an address associated with them. Internetwork names typically are location-independent and remain associated with a device wherever that device moves (for example, from one building to another). Internetwork addresses usually are location-dependent and change when a device is moved (although MAC addresses are an exception to this rule). As with network addresses being mapped to MAC addresses, names are usually mapped to network addresses through some protocol. The Internet uses Domain Name System (DNS) to map the name of a device to its IP address. For example, it’s easier for you to remember http://www.cisco.com instead of some IP address. Therefore, you type http://www.cisco.com into your browser when you want to access Cisco’s web site. Your computer performs a DNS lookup of the IP address for Cisco’s web server and then communicates with it using the network address.
GLOSSARY
1. FTP (File Transfer Protocol) – Used to transfer files over the internet using TCP/IP.
2. HTTP (Hypertext Transfer Protocol) – Underlining protocol used by the World Wide Web. Allows Web servers and browsers to communicate with each other.
3. SMTP (Simple Mail Transfer Protocol) – Protocol used to send email messages between servers.
4. DNS (Domain Name Service) – An internet service that translates domain names, such as http://www.yahoo.com, into IP addresses.
5. TFTP (Trivial File Transfer Protocol) – Simplified version of the FTP protocol which has no security features.
6. NFS (Network File System) – Client/Server application designed by SUN MICROSYSTEMS to allow all network users to access files stored on different computer types.
7. Telnet – terminal emulation program that allows you to connect to a server and enter information and commands similar to if you were actually on the server terminal.
8. ASCII – a code for representing English characters as numbers.
9. EBCDIC (Extended Binary-Coded Decimal Interchange Code) – IBM code for representing characters as numbers.
10. MIDI (Musical Instrument Device Interface) – adopted by the electronic music industry for controlling devices, such as synthesizers and sound cards, that emit music.
11. MPEG (Moving Pictures Experts Group) – the family of digital video compression standards and file formats developed by the ISO group.
12. JPEG (Joint Photographic Experts Group) – a lossy compression format for color images that reduces file size by 5% while losing some image detail.
13. SQL (Structured Query Language) – a standardized query language for requesting information from a database.
14. RPC (Remote Procedure Call) – allows a program on one computer execute a program on a server.
15. TCP (Transmission Control Protocol) – enables two to establish a connection and exchange streams of data.
16. UDP (User Datagram Protocol) – offering a direct way to send and receive datagrams over an IP network with very few error recovery services.
17. IP (Internet Protocol) – specifies the format of packets and the addressing schemes.
18. ICMP (Internet Control Message Protocol) – an extension of IP which supports packets containing error, control, and informational messages.
19. ARP (Address Resolution Protocol) – used to convert an IP address to a physical address.
20. PING – a utility to check if an IP address is accessible.
21. Traceroute – utility that tracks a packet from your computer to an internet host showing how many hops and how long it took.
22. IEEE 802.2 – divides the data link layer into two sublayers — the logical link control (LLC) layer and the media access control (MAC) layer.
23. 802.3 – Defines the MAC layer for bus networks that use CSMA/CD. This is the basis of the Ethernet standard.
24. 802.5 – Defines the MAC layer for token-ring networks.
================================================================