A. Explain the purpose and functionality of IP addressing and subnetting.
IP (Internet Protocol) addresses are used to identify hosts on the campus Internet, a Cornell network that ties into the Internet, a global network. If the computer is attached to Cornell’s network, it needs an IP address to be recognized as part of the campus Internet.
IP addresses are constructed according to a set of specific rules so that hosts on any part of the Internet can communicate with each other. This document describes IP addresses only as they apply to Cornell’s campus network. (If you want to know more about Internet addressing, refer to Internetworking with TCP/IP: Principles, Protocols, and Architecture by Douglas Comer, Prentice Hall).
An IP address consists of a 32-bit binary number, which is typically presented as four decimal numbers (one for each 8-bit byte) separated by decimal points. For example, 128.253.21.58.
A subnet mask defines how many bits are used for the network address and how many for the host address.
The subnet mask address is 255.255.255.0, and it currently is the same for all LANs. If you convert the subnet mask address to its binary form, it looks like this:
Subnet mask: 11111111 11111111 11111111 00000000
If you convert our example host address (128.253.21.58) to its binary form, it looks like this:
Host address: 10000000 11111101 00010101 00111010
Together they look like this:
Subnet mask: 11111111 11111111 11111111 00000000
Host address: 10000000 11111101 00010101 00111010
The subnet mask when shown this way, as an overlay on the host address, essentially tells the computer which part of the IP address is a network address and which part is a host address. Everything in the host address that corresponds to a 1 in the subnet mask is a network address and everything in the host address that corresponds to a 0 in the subnet mask is a host address.
 |
| http://media.packetlife.net/media/library/15/IPv4_Subnetting.pdf |
B. Given an IP address and netmask, determine the Network IP and the Broadcast IP.
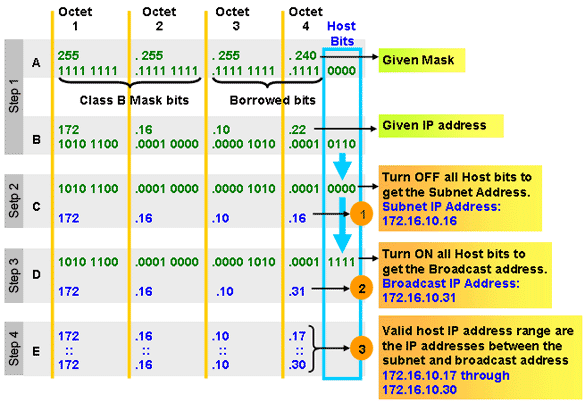 |
| http://ccna-cisco.webs.com/subnetting.htm |
C. Given a routing table and a destination IP address, identify which routing table entry the destination IP address will match.
(from http://en.wikipedia.org/wiki/Routing_table)
In computer networking a routing table, or routing information base (RIB), is a data table stored in a router or a networked computer that lists the routes to particular network destinations, and in some cases, metrics (distances) associated with those routes. The routing table contains information about the topology of the network immediately around it. The construction of routing tables is the primary goal of routing protocols. Static routes are entries made in a routing table by non-automatic means and which are fixed rather than being the result of some network topology “discovery” procedure.
Basics
A routing table uses the same idea that one does when using a map in package delivery. Whenever a node needs to send data to another node on a network, it must first know where to send it. If the node cannot directly connect to the destination node, it has to send it via other nodes along a proper route to the destination node. Most nodes do not try to figure out which route(s) might work; instead, a node will send an IP packet to a gateway in the LAN, which then decides how to route the “package” of data to the correct destination. Each gateway will need to keep track of which way to deliver various packages of data, and for this it uses a Routing Table. A routing table is a database which keeps track of paths, like a map, and allows the gateway to provide this information to the node requesting the information.
With hop-by-hop routing, each routing table lists, for all reachable destinations, the address of the next device along the path to that destination: the next hop. Assuming that the routing tables are consistent, the simple algorithm of relaying packets to their destination’s next hop thus suffices to deliver data anywhere in a network. Hop-by-hop is the fundamental characteristic of the IP Internetwork Layer[1] and the OSI Network Layer.
The primary function of a router is to forward a packet toward its destination network, which is the destination IP address of the packet. To do this, a router needs to search the routing information stored in its routing table.
A routing table is a data file in RAM that is used to store route information about directly connected and remote networks. The routing table contains network/next hop associations. These associations tell a router that a particular destination can be optimally reached by sending the packet to a specific router that represents the “next hop” on the way to the final destination. The next hop association can also be the outgoing or exit interface to the final destination.
The network/exit-interface association can also represent the destination network address of the IP packet. This association occurs on the router’s directly connected networks.
A directly connected network is a network that is directly attached to one of the router interfaces. When a router interface is configured with an IP address and subnet mask, the interface becomes a host on that attached network. The network address and subnet mask of the interface, along with the interface type and number, are entered into the routing table as a directly connected network. When a router forwards a packet to a host, such as a web server, that host is on the same network as a router’s directly connected network.
A remote network is a network that is not directly connected to the router. In other words, a remote network is a network that can only be reached by sending the packet to another router. Remote networks are added to the routing table using either a dynamic routing protocol or by configuring static routes. Dynamic routes are routes to remote networks that were learned automatically by the router, using a dynamic routing protocol. Static routes are routes to networks that a network administrator manually configured.
Difficulties with routing tables.
The need to record routes to large numbers of devices using limited storage space represents a major challenge in routing table construction. In the Internet, the currently dominant address aggregation technology is a bitwise prefix matching scheme called Classless Inter-Domain Routing (CIDR).
Since in a network each node presumably possesses a valid routing table, routing tables must be consistent among the various nodes or routing loops can develop. This is particularly problematic in the hop-by-hop routing model in which the net effect of inconsistent tables in several different routers could be to forward packets in an endless loop. Routing loops have historically plagued routing, and their avoidance is a major design goal of routing protocols.
Contents of routing tables
The routing table consists of at least three information fields:
- the network id: i.e. the destination subnet
- cost/metric: i.e. the cost or metric of the path through which the packet is to be sent
- next hop: The next hop, or gateway, is the address of the next station to which the packet is to be sent on the way to its final destination
Depending on the application and implementation, it can also contain additional values that refine path selection:
- quality of service associated with the route. For example, the U flag indicates that an IP route is up.
- links to filtering criteria/access lists associated with the route
- interface: such as eth0 for the first Ethernet card, eth1 for the second Ethernet card, etc.
Routing tables are also a key aspect of certain security operations, such as unicast reverse path forwarding (uRPF).[2] In this technique, which has several variants, the router also looks up, in the routing table, the source address of the packet. If there exists no route back to the source address, the packet is assumed to be malformed or involved in a network attack, and is dropped.
| Network id | Cost | Next hop |
|---|---|---|
| …….. | …….. | …….. |
| …….. | …….. | …….. |
Shown below is an example of what the table above could look like on an average computer connected to the internet via a home router:
| Network Destination | Netmask | Gateway | Interface | Metric |
|---|---|---|---|---|
| 0.0.0.0 | 0.0.0.0 | 192.168.0.1 | 192.168.0.100 | 10 |
| 127.0.0.0 | 255.0.0.0 | 127.0.0.1 | 127.0.0.1 | 1 |
| 192.168.0.0 | 255.255.255.0 | 192.168.0.100 | 192.168.0.100 | 10 |
| 192.168.0.100 | 255.255.255.255 | 127.0.0.1 | 127.0.0.1 | 10 |
| 192.168.0.255 | 255.255.255.255 | 192.168.0.100 | 192.168.0.100 | 10 |
- The columns Network Destination and Netmask together describe the Network id as mentioned earlier. For example, destination 192.168.0.0 and netmask 255.255.255.0 can be written as network id192.168.0.0/24.
- The Gateway column contains the same information as the Next hop, i. e. it points to the gateway through which the network can be reached.
- The Interface indicates what locally available interface is responsible for reaching the gateway. In this example, gateway 192.168.0.1 (the internet router) can be reached through the local network card with address 192.168.0.100.
- Finally, the Metric indicates the associated cost of using the indicated route. This is useful for determining the efficiency of a certain route from two points in a network. In this example, it is more efficient to communicate with the computer itself through the use of address 127.0.0.1 (called “localhost”) than it would be through 192.168.0.100 (the IP address of the local network card).
Forwarding table
Routing tables are generally not used directly for packet forwarding in modern router architectures; instead, they are used to generate the information for a smaller forwarding table. A forwarding table contains only the routes which are chosen by the routing algorithm as preferred routes for packet forwarding. It is often in a compressed or pre-compiled format that is optimized for hardware storage and lookup.
This router architecture separates the Control Plane function of the routing table from the Forwarding Plane function of the forwarding table. [3] This separation of control and forwarding provides uninterrupted performance.

References
- ^ Requirements for IPv4 Routers, F. Baker, RFC 1812, June 1995
- ^ Ingress Filtering for Multihomed Networks,RFC 3704, F. Baker & P. Savola,March 2004
- ^ Forwarding and Control Element Separation (ForCES) Framework, L. Yang et al., RFC3746,April 2004.
- http://technet.microsoft.com/en-us/library/cc779122(WS.10).aspx
D. Explain the purpose and functionality of routing protocols
Routing protocols are used in the implementation of routing algorithms to facilitate the exchange of routing information between networks, allowing routers to build routing tables dynamically. Routers talk to one another about the state of the network and of nearby devices. The protocols they use for to talk to each other, routing protocols, should not be confused with ROUTED protocols like IP and IPX that carry data on the network.
Common routing protocols include RIP, RIPv2, IGRP, EIGRP, IS-IS and BGP. For the CCNA exam you will need to be well versed in RIP, RIPv2, IGRP and EIGRP. You should be aware of IS-IS and BGP, and be able to configure basic OSPF.
Two main types of routing protocols exist – distance vector and link state. A third type known as balanced hybrid (Known now as “Advanced Distance Vector“) combines features of both link state and distance vector protocols.

E. Explain the purpose of fragmentation.
The Internet Protocol (IP) implements datagram fragmentation, breaking it into smaller pieces, so that packets may be formed that can pass through a link with a smaller maximum transmission unit (MTU) than the original datagram size.When an Internet router has multiple parallel paths, technologies like LAG and CEF split traffic across the links according to a hash algorithm. One goal of the algorithm is to ensure all packets of the same flow are sent out the same path to minimize unnecessary packet reordering. Fragmentation reduces efficiency and increases the chances of part of a TCP segment being lost, resulting in the entire segment needing to be retransmitted.



F. Given a fragment, identify what information is needed for reassembly
Fragmentation and reassembly
The Internet Protocol enables networks to communicate with one another. The design accommodates networks of diverse physical nature; it is independent of the underlying transmission technology used in the Link Layer. Networks with different hardware usually vary not only in transmission speed, but also in the maximum transmission unit (MTU). When one network wants to transmit datagrams to a network with a smaller MTU, it may fragment its datagrams. In IPv4, this function was placed at the Internet Layer, and is performed in IPv4 routers, which thus only require this layer as the highest one implemented in their design.
In contrast, IPv6, the next generation of the Internet Protocol, does not allow routers to perform fragmentation; hosts must determine the path MTU before sending datagrams.
Fragmentation
When a router receives a packet, it examines the destination address and determines the outgoing interface to use and that interface’s MTU. If the packet size is bigger than the MTU, and the Do not Fragment (DF) bit in the packet’s header set to 0; the router may fragment the packet.
The router divides the packet into segments. The max size of each segment is the MTU minus the IP header size (20 bytes minimum; 60 bytes maximum). The router puts each segment into its own packet, each fragment packet having following changes:
- The total length field is the segment size.
- The more fragments (MF) flag is set for all segments except the last one, which is set to 0.
- The fragment offset field is set, based on the offset of the segment in the original data payload. This is measured in units of eight-byte blocks.
- The header checksum field is recomputed.
For example, for an MTU of 1,500 bytes and a header size of 20 bytes, the fragment offsets would be multiples of (1500–20)/8 = 185. These multiples are 0, 185, 370, 555, 740, …
It is possible for a packet to be fragmented at one router, and for the fragments to be fragmented at another router. For example, consider a packet with a data size of 4,500 bytes, no options, and a header size of 20 bytes. So the packet size is 4,520 bytes. Assume that the packet travels over a link with an MTU of 2,500 bytes. Then it will become two fragments:

Note how we get the offsets from the data sizes:Note that the fragments preserve the data size: 2480 + 2020 = 4500.
- 0.
- 0 + 2480/8 = 310.
Assume that these fragments reach a link with an MTU of 1,500 bytes. Each fragment will become two fragments:
| Fragment | Total bytes | Header bytes | Data bytes | “More fragments” flag | Fragment offset (8-byte blocks) |
|---|---|---|---|---|---|
| 1 | 1500 | 20 | 1480 | 1 | 0 |
| 2 | 1020 | 20 | 1000 | 1 | 185 |
| 3 | 1500 | 20 | 1480 | 1 | 310 |
| 4 | 560 | 20 | 540 | 0 | 495 |
Note that the fragments preserve the data size: 1480 + 1000 = 2480, and 1480 + 540 = 2020.
Note how we get the offsets from the data sizes:
- 0.
- 0 + 1480/8 = 185
- 185 + 1000/8 = 310
- 310 + 1480/8 = 495
We can use the last offset and last data size to calculate the total data size: 495*8 + 540 = 3960 + 540 = 4500.
Reassembly
A receiver knows that a packet is a fragment if at least one of the following conditions is true:
- The “more fragments” flag is set. (This is true for all fragments except the last.)
- The “fragment offset” field is nonzero. (This is true for all fragments except the first.)
The receiver identifies matching fragments using the identification field. The receiver will reassemble the data from fragments with the same identification field using both the fragment offset and the more fragments flag. When the receiver receives the last fragment (which has the “more fragments” flag set to 0), it can calculate the length of the original data payload, by multiplying the last fragment’s offset by eight, and adding the last fragment’s data size. In the example above, this calculation was 495*8 + 540 = 4500 bytes.
When the receiver has all the fragments, it can put them in the correct order, by using their offsets. It can then pass their data up the stack for further processing.
G. Explain the purpose of TTL functionality
An eight-bit time to live field helps prevent datagrams from persisting (e.g. going in circles) on an internet. This field limits a datagram’s lifetime. It is specified in seconds, but time intervals less than 1 second are rounded up to 1. In practice, the field has become a hop count—when the datagram arrives at a router, the router decrements the TTL field by one. When the TTL field hits zero, the router discards the packet and typically sends an ICMP Time Exceeded message to the sender. The program traceroute uses these ICMP Time Exceeded messages to print the routers used by packets to go from the source to the destination.
H. Given a packet traversing a topology, document the source/destination IP address/MAC address changes at each hop.
-
The Source and Destination IP address is not going to change. Host 1 IP address will stay as being the source IP and the Host 2 IP address will stay the destination IP address. Those two are not going to change.For the MAC address it is going to change each time it goes from one hope to another. (Except switches… they don’t change anything)Frame leaving HOST 1 is going to have a source MAC of Host 1 and a destination MAC of Router 1.Router 1 is going to strip that info off and then will make the source MAC address of Router1’s exiting interface, and making Router2’s interface as the destination MAC address.Then the same will happen… Router2 is going to change the source/destination info to the source MAC being the Router2 interface that it is going out, and the destination will be Host2’s MAC address.In a nutshell that is about what happens.
Leave a Reply