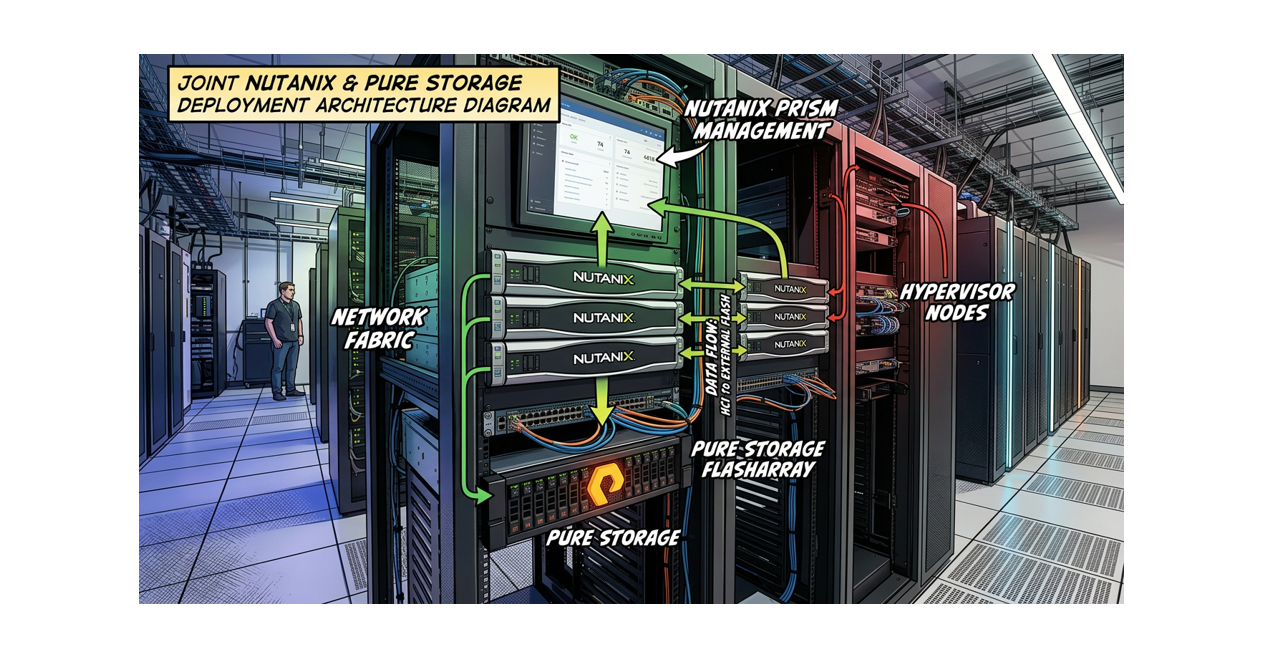
Hyperconverged infrastructure ships compute and storage in the same box, and for most workloads that is exactly what you want. The trouble starts when the two axes grow at different rates. You add nodes to get more IOPS you do not need, or you buy capacity and inherit CPU cores that sit idle. Nutanix Cloud Platform with Dell PowerStore breaks that coupling. The compute tier runs AOS and AHV on industry standard servers with no local data disks, and it consumes an external Dell PowerStore array over NVMe/TCP. You size and grow each tier on its own.
This is a two tier, disaggregated design. A single PowerStore array can serve several NCI compute clusters, and a compute cluster can scale without touching a single drive on the storage side. What follows walks the architecture, the hard requirements, the deployment sequence, and the day to day operations, with the practitioner gates called out where they matter. Everything here maps to the NCP with Dell PowerStore 7.6 material.
Architecture: what you are actually building
Two components carry the whole solution. The NCI compute cluster runs Nutanix AOS and AHV on standard servers. It hosts your guest VMs, and it delivers the parts you expect from Nutanix: VM availability, security and microsegmentation through Nutanix Flow, disaster recovery, and lifecycle management through Prism Central. The cluster holds no local data disks. Every AOS vDisk is a volume that lives on the array.
The Dell PowerStore array is the dedicated storage tier. It presents volumes over NVMe/TCP, serves as the endpoint for that traffic from the hosts and Controller VMs, and answers authenticated REST API calls from PowerStore Manager for discovery, host mapping, and data copy operations. Because it runs independently of the compute layer, you scale storage without affecting compute capacity, and the reverse.
FIG. 1: The compute tier holds no data disks. Each AOS vDisk maps to a PowerStore volume, reached over NVMe/TCP across redundant switch fabrics.
The vocabulary you need
A handful of terms carry the design. The NCI compute cluster is the compute construct built from supported standard servers. The Controller VM (CVM) is the AOS storage engine that runs on every node and handles user I/O, data placement, and metadata. Nutanix Foundation Central images the nodes and creates the cluster. On the storage side, PowerStoreOS is the container based operating system on the array, a volume is the block level device presented to hosts over FC, iSCSI, or NVMe-oF, and NVMe over TCP is the transport that carries array access across a standard TCP fabric.
Requirements: the floor before you start
Compute node minimums are firm. Each node needs at least 64 GB RAM, four physical network ports spread across at least two NICs, and a boot controller on the Nutanix hardware compatibility list with 960 GB usable in RAID1. Networking has to be 10 Gb end to end from the compute cluster to the array, sized for the performance you actually need, with MTU 9000 as an optional but recommended setting.
Foundation Central carves a fixed slice out of each node for the CVM: 16 logical cores, 16 physical cores per socket, and 32 GiB of vRAM. The host CPU has to carry at least as many physical cores in a single NUMA node as the CVM needs logical cores, so plan the socket layout with that in mind.
WATCH, CVM sizing. The 16 logical core requirement has to fit inside one NUMA node. If your CPU has fewer than 16 physical cores per socket, the CVM allocation crosses NUMA boundaries and you lose the locality the storage path depends on. Verify core per socket counts before you buy.
On the storage side the setup supports the PowerStore T and later block families. The following models are called out as supported:
BLOCKER, single appliance only. Configure the PowerStore as a single appliance cluster. Multi appliance clusters are not supported, and you must not expand a single appliance cluster into a multi appliance one while it backs Nutanix. This is an architectural constraint, not a preference. Plan capacity within one appliance from day one.
Software compatibility
The integration pins specific versions together. Treat this as a set, not a menu, and confirm the current numbers against the Nutanix portal before you image anything, since point releases move.
Component
Version
AOS
7.6
AHV
11.2
Foundation Central
2.2
Prism Central
7.6
Nutanix Move
6.3.0
PowerStoreOS
5.0.0.2 or higher
Table 1: Compatible software versions.
What the solution does not do
The exclusions matter as much as the requirements, because each one is a design decision you cannot walk back later:
No one node or two node compute clusters, in production or anywhere else. The floor is three nodes.
No Repair Host Boot Disk workflow in Prism Element.
No layered products. NDB, NUS, and NDK are out.
No RDMA and no iSER for external storage service segmentation.
No container capacity reservation when you configure external storage.
Network: segmentation and the switch layout
Storage traffic gets its own path. The reference topology connects the compute nodes to the array through two redundant switch fabrics using four VLANs for storage. On each node, the default virtual switch vs0 carries management, live migration, DR replication, and application traffic on Eth0 and Eth2. A separate switch vs1 carries data traffic only on Eth1 and Eth3. IPMI stays on its own out of band path.
FIG. 2: Storage rides vs1 across two fabrics. Each PowerStore node gets one address per storage VLAN, so with two storage VLANs each node carries two addresses.
Network segmentation is configured from Prism Element only. Nutanix recommends LACP on the switch ports that carry storage, and jumbo frames on the physical ports between the cluster and the array. The vs1 switch is optional but recommended, and it wants at least two physical NICs.
BLOCKER, the 192.168.5.0/24 overlap. Do not assign storage addresses from a subnet that overlaps 192.168.5.0/24. AOS uses an internal virtual switch on that range on the default VLAN to talk between the CVM and the hypervisor. An overlap breaks that path. If you truly need that space, put it on a different VLAN. This one silently wrecks clusters that otherwise look healthy.
When you build the internal interface for external storage you provide a descriptive name, the compute cluster VLAN ID, the storage virtual switch, and an IP pool with a start and end address. Size that pool with headroom. Nutanix recommends provisioning it for up to 32 nodes so future growth does not force a rework. Each host draws one address from the pool, and you add at least as many addresses to the range as you have nodes.
Deploy: the sequence, in order
Deployment is strictly sequential. Do not improvise the order, because two of these steps have hard dependencies on the ones before them.
Stand up the PowerStore infrastructure. Create the cluster with the Initial Configuration Wizard, set the management network, and build two dedicated NVMe over TCP storage networks, one per fabric, mapped to different front end ports on both nodes.
Download AOS and AHV and image the nodes. Pull the packages from the Nutanix portal and image the compute nodes with Foundation Central.
Create the NCI compute cluster from the imaged nodes, in standalone or managed mode.
Create the internal interface for network segmentation so storage traffic is isolated to the array.
Attach the PowerStore array to the compute cluster as external storage.
Install Prism Central to manage the cluster and to manage external storage for other registered clusters.
BLOCKER, external storage comes first. After the cluster is up, configure external storage before you create any storage container or VM. The AHV boot disks cannot hold VM data, so the system prompts you to set up external storage first and refuses container or VM creation until you do. Create a container or VM early and the operation fails outright.
Building the internal interface
In Prism Element, go to Settings > Network > Network Configuration, open the Internal Interfaces tab, and choose Create New Interface. On the interface details, give it a descriptive name such as External Storage LAN, enter the VLAN ID that is already live on the physical switch, and pick the storage virtual switch. Create an IP pool with a netmask and one or more ranges, adding at least one address per node.
On the feature selection step, turn on the External Storage toggle to isolate the traffic, then set the MTU. The field accepts 1280 to 9000, and Nutanix recommends 9000 for PowerStore. Leave it blank and the system falls back to 1500. If the array sits on a subnet that is not reachable at layer 2, use the advanced settings to supply both destination subnets and a gateway, since the CVM then has to route to reach it. Save, then enable.
WATCH, interface build time. Creating the internal interface takes three to eight minutes depending on cluster size. You cannot attach external storage until that task finishes, so build this in before you plan the attach window rather than watching a spinner during a cutover.
Attaching the array
You can attach from either Prism Element or Prism Central. In Prism Element the flow is Storage > Attach External Storage, then Initial Setup, Connection Details, and Storage Details. Select Dell PowerStore as the vendor, give the cluster IP or FQDN of the array, and supply credentials for an account with at least Storage Operator permissions. Name the external storage entity and attach. PowerStore exposes the full array rather than a carved out slice, so there is no sub section to select.
From Prism Central, the path is the Infrastructure app, then Storage > External Storage > Attach External Storage. The compute cluster has to run AOS 7.6 or later, and if the array is on a separate data network you enable network segmentation before you attach. The name accepts up to 75 characters and allows letters, numbers, periods, hyphens, underscores, and the hash character.
WATCH, two hours of red is normal. After the attach, the Health and Cluster Resiliency indicators sit at Critical for roughly two hours, then settle to Healthy. Do not open a ticket or start pulling the deployment apart during that window. It is expected behavior, not a fault.
BLOCKER, two rules you cannot break. You can attach exactly one external storage device to the compute cluster. You can update it, but you cannot delete it, so get the connection details right. And never delete, map, unmap, or modify any PowerStore volume whose name begins with the nx- prefix. Those belong to Nutanix. Touching them corrupts the cluster.
Operate: availability, upgrades, and the ground rule
Because VM data lives on the array in its own availability domain, VM availability is bounded by surviving compute and array reachability, not by a fault tolerance level inside the cluster. That changes the failure math. An N node cluster tolerates the simultaneous failure of up to N minus 3 nodes, which is to say three nodes have to keep running. Cluster service data sits on dedicated volumes on the array, so after a multi node failure the cluster resumes services on the surviving nodes without hand holding. By default a node retries I/O until the array answers, and you can set a per VM force shutdown timeout to restart affected VMs on a node that still has a path to storage.
Software and firmware split cleanly
Software and firmware take different tracks. Use Nutanix LCM to update AOS and AHV on the compute nodes without downtime. LCM does not handle server firmware and BIOS. For Dell Private Cloud managed servers, use the Dell Automation Platform. For everything else on the compute HCL, including Dell PowerEdge servers that DPC does not manage, upgrade firmware and BIOS by hand: place the node in Nutanix maintenance mode, run the vendor tools, exit maintenance mode, wait for the cluster to report healthy, then move to the next node.
BLOCKER, manage through Prism, never the array. Perform every user action through Prism Central or Prism Element. Do not use PowerStore Manager to modify volumes. The Nutanix control plane owns the volume lifecycle here, and out of band changes on the array put the two views out of sync in ways that are painful to untangle.
Migrating in from ESXi
For existing ESXi and PowerStore estates, you migrate to AHV with Nutanix Move. Move handles ESXi to AHV, but note the constraint that shapes your cutover plan: it supports offline migration only. There is no online path, so every workload takes a maintenance window.
Limits: numbers worth keeping nearby
Two scale ceilings govern the design. The AOS side caps what the cluster can present, and the PowerStore side caps what the array can hold. Size against both.
Limit
Value
Containers per cluster
256
Size per vDisk
256 TB
vDisks per cluster
5000
Volume groups per cluster
2000
Table 2: AOS storage cluster maximums.
Metric
500
1200
3200
5200
9200
Volumes and clones per appliance
1500
6000
10000
16000
32000
Max volume size (TB)
256
256
256
256
256
Volume mappings per appliance
24000
40000
60000
64000
96000
Snapshots per volume or clone
256
512
512
512
512
Block volume snapshots per appliance
50000
150000
200000
250000
350000
Table 3: Dell PowerStore maximums by base model.
These PowerStore figures shift across releases and the table does not cover every model, so confirm the current numbers in the Dell PowerStore support matrix before you commit a design to them.
Close: when this design earns its keep
Disaggregation is not free. You take on a second management surface, a storage fabric to design, and a set of gates that punish improvisation. What you get back is the ability to grow compute and storage on their own clocks, to keep an existing PowerStore investment in play under Nutanix management, and to run AHV with Flow, DR, and Prism Central over storage that is already sized for NVMe. If your compute and capacity curves have drifted apart, that trade is worth making. If they track each other, standard hyperconverged is still the simpler answer.
The through line across every section above is the same: the gates are not suggestions. Three nodes minimum, single appliance PowerStore, external storage before any VM, stay off the nx- volumes, and drive everything through Prism. Get those right and the rest is a clean, sequential build.
Reference: Nutanix Cloud Platform with Dell PowerStore Deployment Guide, NCP with Dell PowerStore 7.6. Version numbers and configuration maximums move between releases; verify against the Nutanix portal and the Dell PowerStore support matrix before you build.
If you have run Cisco UCS for any length of time, you know the building blocks by heart: policies, profiles, and templates managed through UCS Manager. Intersight Managed Mode keeps those exact concepts but moves the control point into Intersight. The good news is that you do not have to rebuild a domain by hand to get there. Cisco ships a free virtual appliance, the Intersight Managed Mode Transition Tool, that reads your live configuration, converts it, and in its newest mode performs the cutover for you.
This post walks through what the tool does, how UCSM Managed Mode and Intersight Managed Mode differ, and the full in place migration flow as it actually runs, including the few manual gates that catch people the first time.
At a glance
IMM is a software stack for Fabric Interconnects that puts UCS configuration and lifecycle under Intersight instead of UCS Manager.
The IMM Transition Tool is an OVA you deploy on vSphere. It replicates UCSM or UCS Central configuration and converts Service Profiles and Templates into Server Profiles and Templates.
Identities carry over. UUIDs, MAC addresses, WWNNs, WWPNs, IQNs, and IP addresses are preserved so a migrated server keeps its identity.
The tool offers five transition types. The headline one, In-Place UCS Domain Migration, automates fetch, convert, push, backup, erase, setup, claim, and domain deploy. You finish by deploying server profiles manually.
Latest release is 5.1.3 (January 2026). The automated in place migration arrived in 5.0.1.
UMM and IMM are the same parts, arranged differently
UCSM Managed Mode, often shortened to UMM, is the model most of us have run for years. An administrator builds policies, rolls them into a service profile, optionally wraps that in a template, and applies it to a server. Each domain is configured on its own, and the configuration lives on the Fabric Interconnects under UCS Manager.
Intersight Managed Mode reuses the same vocabulary. You still have policies, profiles, and templates. What changes is where they live and how they are reused. In IMM, those objects sit in Intersight and can be shared across many servers and many domains from one place. The Fabric Interconnects run a new software stack built on a Redfish based standard model, and Intersight becomes the single pane that supervises both standalone servers and Fabric Interconnect attached systems. Your existing knowledge carries over. You are applying what you already know in a more modular, more scalable structure.
UMM versus IMM. Same building blocks, different center of gravity. In UMM the configuration is built and held per domain. In IMM the same objects live in Intersight and are reused across many servers and domains.
Dimension
UCSM Managed Mode (UMM)
Intersight Managed Mode (IMM)
Control point
UCS Manager on the Fabric Interconnects
Intersight, SaaS or appliance
Building blocks
Policies, profiles, templates
Policies, profiles, templates (same concepts)
Reuse model
Per domain configuration
Objects shared across servers and domains
Server object
Service Profile and Service Profile Template
Server Profile and Server Profile Template
Underpinning
UCS Manager object model
Redfish based standard model
Scope of view
Domain by domain
Standalone and Fabric Interconnect attached, one pane
What the IMM Transition Tool actually does
The tool is a prebuilt virtual appliance. You point it at a running UCS Manager domain or a UCS Central instance and it fetches the entire configuration and inventory over HTTPS. From there it validates hardware and software compatibility against Intersight, converts the logical objects, and can push the result into your destination Intersight account.
The conversion does two things that matter for a clean cutover. First, it maps the Service Profile model onto the Server Profile model, including the policies and pools attached to each profile. Second, and this is the part that lets a physical server keep working after the move, it preserves the configuration identifiers that a server gets from its profile. That means UUIDs, MAC addresses, WWNNs, WWPNs, IQNs, and IP addresses come across rather than being regenerated.
Conversion at a glance. Service Profiles and Templates become Server Profiles and Templates. Attached policies and pools come with them, and the server identities are preserved rather than reissued.
Five transition types, one tool
When you click Add IMM Transition, you pick a transition type. They range from a read only assessment to a fully automated cutover. Choosing the right one is the first real decision in any project.
Transition type
What it does
Generate Readiness Report
Assessment only. Produces the compatibility and readiness summary for a UCS Manager domain or a UCS Central configuration. Nothing is pushed.
Generate Readiness Report + Push Config to Intersight
Converts the configuration and pushes it into Intersight, building the policies, pools, profiles, and templates in your account without touching the source domain.
In-Place UCS Domain Migration
Available from release 5.0.1. The automated end to end path. Fetches and converts, backs up UCSM, erases or changes the mode on the Fabric Interconnects, runs initial setup, claims them, then assigns and deploys the domain profile.
Clone Intersight
Copies configuration from one Intersight account to another, across SaaS, Connected Virtual Appliance, and Private Virtual Appliance accounts.
Upload Configuration + Push to Intersight
Takes a JSON configuration file you provide and pushes it straight to Intersight.
Conversion versus in place
The push only conversion stands up your configuration in Intersight alongside the running UCSM domain, which suits a side by side or staged adoption. The in place migration is the one that actually moves an existing domain over and reconfigures the hardware in IMM. Use the readiness report first either way. It is the same engine under both, and it tells you what will and will not convert before anything changes.
Before you start
Sizing and connectivity
The appliance is modest. The minimum is 2 vCPUs, 8 GB of RAM, and 100 GB of storage, with an optional extra 10 GB to 5000 GB if you plan to use the built in Software Repository for OS and firmware images. Plan the network for the ports the tool needs.
TCP 443 (HTTPS) for the tool UI and for talking to UCS Manager, UCS Central, and Intersight.
TCP 22 (SSH) for troubleshooting and advanced configuration.
DNS on TCP and UDP 53, and NTP on UDP 123.
For an in place migration specifically, both 443 and 22 must reach each Fabric Interconnect IP. The tool uses them for the erase, setup, and claim steps.
Supported source versions are UCS Manager 3.2(1d) or later and UCS Central 2.0(1a) or later. The appliance is delivered as an OVA at virtual hardware version 11 and runs on ESXi 6.0 or later.
Three gates that catch people on an in place run
These come straight from a real run of the tool. Handle them before you reach the erase step or the validation will stop you.
Unclaim the domain first. The source UCS Manager domain must not already be claimed by the destination Intersight account. If it is, the pre assignment of server profiles to server serial numbers will not work. Unclaim it from Intersight before you start, and confirm in the UCS Manager device connector that it shows unclaimed.
Set the password encryption key. If you want passwords in converted policies to remain intact, set the password encryption key in UCS Manager and remember it. From UCS Manager 4.2(3d) and later you cannot create or import a backup configuration without it, and the in place flow takes a full state backup.
Power off the servers. The erase validation requires every server in the domain to be powered off so the domain is in a clean state before it is reconfigured in IMM. Shut them down cleanly and retry the validation if it flags one.
HyperFlex
If your UCSM domain has any HyperFlex cluster deployed, do not migrate it to IMM. HyperFlex servers are not currently supported in Intersight Managed Mode.
Deploying and reaching the appliance
Download the OVA from the UCS Tools page at ucstools.cloudapps.cisco.com, then deploy it through vCenter. Direct deployment from an ESXi host is not supported and tends to fail, so use the vSphere Web Client.
Deploy the OVF template. In the vSphere Web Client, right click the host or cluster, choose Deploy OVF Template, and point it at the downloaded OVA.
Customize the template. Enter the network settings and set the system password. The NTP field is mandatory and defaults to ntp.ubuntu.com. Set the Software Repository disk size if you want it, between 10 and 5000.
Finish, power on, and open the console to confirm the VM is up.
Sign in. Browse to https://<VM IP>. HTTP redirects to HTTPS. Log in as admin with the password you set during deployment. The session times out after 30 minutes of inactivity.
An auto generated default password is substituted into converted policies that carry secrets, such as Virtual Media and iSCSI Boot, and a separate one is used for Mutual CHAP in iSCSI Boot. Plan to reset those on the converted policies after they land in Intersight.
The in place migration, step by step
This is the path that moves a live domain. The tool drives the sequence, pausing at the points where you need to make a decision or take a manual action. The flow below groups the work into four phases.
The in place migration in four phases. Prepare the environment, convert and push the configuration, cut over the Fabric Interconnects, then activate the servers. Everything through server discovery is automated; deploying the server profiles is the manual finish.
Phase 1: Prepare
This is the work you do in UCS Manager and Intersight before you open a transition. Unclaim the source domain from the destination Intersight account, set the password encryption key in UCS Manager, confirm that 443 and 22 reach both Fabric Interconnects, and power off every server in the domain. The first three save you from a failed validation later. The power off is enforced at the erase step.
Phase 2: Convert and push
Now you build the transition. Click Add IMM Transition, name it, choose In-Place UCS Domain Migration, and the tool shows a short guided tour of the steps before you Start.
Add the source. Select an existing UCS Manager device or add a new one with its IP or FQDN, username, password, and a user label. Refresh so the latest configuration and inventory are pulled in. On a sizeable domain this takes a few minutes, with progress shown on the right.
Add the destination. Choose an existing Intersight account or add a new one. A new SaaS or appliance account needs an API Key ID and Secret Key, which you generate in Intersight under Settings, API, API Keys. For SaaS you also pick the region, US or EU.
Set the transition settings. Tags, fabric policy targets, and profile options live here. From release 5.1.2 the tool can configure vCon to PCI slot mappings automatically.
Select profiles and templates. All are selected by default. The tool warns on profiles in an invalid state, such as a pending reboot or a configuration failure, and warns again if you push more than 100 profiles.
Map organizations. Choose Default Mapping to mirror your UCS org names into Intersight, or Advanced Mapping to fold several UCS orgs into one Intersight org. In a simple lab you might map root straight to the default Intersight org.
Generate and read the report. The readiness report is produced once and cannot be regenerated for that config, so review it carefully. Errors must be resolved before you continue. Warnings can be acknowledged, but understand each one first.
Push the configuration. The converted objects are committed to Intersight. The push summary marks each object Success, Skipped, or Failed, with a detail view per object.
Phase 3: Cut over the Fabric Interconnects
This is the irreversible part, which is why the tool takes a backup first.
Backup. A full state backup of the UCSM setup is taken so a rollback is possible. Download it and keep it somewhere safe.
Erase or change mode. Two options. Erase Configuration resets the Fabric Interconnects to factory defaults and then reconfigures them in IMM, with initial setup done by DHCP or manually on the console. Change Mode switches the Fabric Interconnects to Intersight Managed Mode on reboot with no initial setup at all, which removes the DHCP and console work. Change Mode needs FI firmware 4.3(5c) or later and the tool at 5.0.3 or later. Before either runs, the tool validates that servers are powered off, the domain is unclaimed, and both protocols reach both FIs.
Initial setup. If you chose Erase and have DHCP, enter the IP details and the tool completes setup automatically. Without DHCP, connect a console cable to each Fabric Interconnect and enter the values the tool displays, the management IP, subnet, gateway, and DNS, one FI at a time.
Claim to Intersight. The tool claims the Fabric Interconnects, with an optional proxy if your device connectors need one.
Phase 4: Activate
With the Fabric Interconnects claimed, the tool assigns and deploys the converted domain profile, then triggers discovery so the servers appear in Intersight.
The one manual step at the end
After discovery, the tool stops. The server profiles are pre assigned to the server serial numbers, but deployment is not automated. You power on each server and deploy its server profile to finish the move. From release 5.1.3 there is also an optional step to push equipment specific items such as chassis and server labels, tags, and SPAN sessions, once the equipment is claimed and discovered.
Reading the readiness report
The report is the same engine behind every transition type, and it is where you decide whether a domain is ready. It is organized into a few sections.
Conversion score. Score meters for hardware compatibility and fabric configuration, both for UCS Manager domains, and for server policy configuration. The rating reads as Excellent, Very Good, Good, or Poor. Cisco notes the rating reflects general cases, so read the detail for your environment.
Overall summary. The attention points list the errors and warnings to address first. Errors are unsupported elements; warnings are elements that cannot be fully converted. Hardware compatibility shows pie charts per component, where green is compatible, orange means a firmware upgrade is needed, and red means not currently compatible. The config conversion summary maps each source object to its converted Intersight object.
Hardware compatibility detail. Component by component tables for Fabric Interconnects, chassis, racks, adapters, and the rest, color coded the same way.
Config conversion detail. Per object tables showing the attributes used, the source to destination mapping, and boot order, with the same warning and error coding.
Source config reference. The pool details from the source domain, including which IP addresses are assigned to which service profiles and physical servers.
A note on timing
Report generation and the push are not instant. On a large UCS Manager configuration with many connected servers, Cisco warns that some operations can take more than an hour. Plan your maintenance window with that in mind rather than assuming a few minutes.
Which path should you take
If you are assessing, start with Generate Readiness Report. It is free of risk and it tells you where the firmware upgrades and the unsupported objects are. If you are adopting IMM gradually or building a new account, the conversion with push lets you stand everything up in Intersight while the UCSM domain keeps running. When you are ready to actually move a domain and reconfigure its hardware, the in place migration is the path that does it, with backup and validation built in. In every case, let the readiness report guide the work. It is the cheapest hour you will spend on the project.
The headline is simple. The concepts you already know in UCS Manager carry directly into Intersight Managed Mode, and the transition tool removes most of the manual conversion and a good deal of the risk. The parts that stay in your hands are the preparation gates and the final server profile deployment, and both are easy once you know they are coming.
Source material for this walkthrough: the Cisco Intersight Managed Mode Transition Tool User Guide, 5.x, and the Release Notes for the IMM Transition Tool, current to release 5.1.3, dated January 2026. Verify exact behavior against the documentation for the specific release you deploy, since features and limits change between point releases.
Javier E. Rodriguez, PE School of Cybersecurity and Privacy Georgia Institute of Technology javirodz@gatech.edu
Abstract
This paper presents the design and implementation of a behavioral ransomware detector built with machine learning. The system models the input and output (I/O) patterns of a virtual machine in two states: at steady state, and while its files are being encrypted by a typical ransomware attack. The model relies on key performance indicators (KPIs) that are available in most modern storage arrays, together with Azure Machine Learning Studio in the Microsoft Azure cloud. This combination keeps the method accessible to practitioners who do not have specialized knowledge of ransomware internals or machine learning.
Data collection takes place at the storage array level through the Nutanix distributed data cluster. Observing I/O at this layer makes the measurement invisible to adversarial ransomware running inside the guest operating system. Because the method is behavioral, it can be expressed as anomaly detection, which allows it to provide a general detection capability against previously unseen, zero day ransomware.
The experiments show that, once a virtual machine reaches steady state I/O, the model reacts to the anomalies caused by active encryption with very high accuracy.
1. Introduction
According to several industry reports, including the CrowdStrike Global Threat Report [1] and guidance from the Cybersecurity and Infrastructure Security Agency (CISA) [2], ransomware remains one of the most visible cybersecurity risks. The practice will continue for as long as it stays profitable. Estimates of its cost vary, but they consistently exceed the billion dollar mark, and industry coverage describes a threat that keeps evolving in both scale and technique [3].
The average ransom payment nearly doubled in the year preceding this study, yet that figure is small next to the cost of downtime. PurpleSec reported that the average cost of downtime per incident in 2020 was approximately $283,000 [4]. The growth in attacks reached every sector, public and private. Readers should treat that figure as a vendor reported estimate and verify it against a primary source before citing it independently.
The central difficulty in detecting ransomware is that it uses the same libraries and system calls as legitimate applications and routine operating system tasks. By taking a generic approach built on off the shelf tools, the system described here aims to address that difficulty without depending on signatures specific to any one family.
2. Background
Ransomware is a class of malware that denies a user access to their data until a ransom is paid [5]. The threat actor demands payment in exchange for restoring the data, which may be anything held in the system’s storage. The goal is to prevent victims from carrying out their normal activities (see Figure 1).
Figure 1. Steps in ransomware activity [6].
Ransomware is commonly divided into two basic types, locker and crypto, with hybrid variants in some cases [6]. The approach in this study targets crypto ransomware, which encrypts the victim’s original data and renders it unavailable. The scheme typically includes a ransom note with instructions for paying and for obtaining the key needed to decrypt the data. This is an attack against the availability of the system.
In some cases the threat actor also exfiltrates the data and threatens to publish it unless the ransom is paid. That tactic attacks the confidentiality of the data and can expose victims to regulatory fines, for example when the data includes payment card information or medical history.
2.1 Technology Overview
Figure 2 shows the technology used in the laboratory setting. The top layer, labeled App, holds the virtual machine running the Windows 10 operating system. The left side of the figure shows the conceptual layout of a hyperconverged system, and the right side shows the physical equipment used in the experiments.
Figure 2. The legacy three tier infrastructure consists of three layers: the compute layer, the storage area network or fabric (SAN), and the storage array or arrays [7].
Hyperconverged infrastructure (HCI) is a software defined, unified system that combines the conventional data center elements of storage, compute, networking, and management. It uses software and x86 servers in place of expensive, purpose built hardware, which reduces data center complexity and improves scalability through a single, simple console. The laboratory equipment used in these experiments is a Nutanix hyperconverged cluster running the Acropolis hypervisor. The second part of the laboratory environment runs in the Azure cloud and is described in the Analysis section.
3. Literature Review
Dozens of studies address ransomware detection using a wide range of techniques. A substantial body of work applies machine learning and dynamic analysis to the problem, including wrapper based feature selection [8], network traffic analysis [9], [10], software defined networking [11], behavioral classification of variants [12], layered machine learning defenses [13], finite state machine models [14], and broad surveys of the field [15], [6], [16], [17]. Behavior based automated malware analysis has also been studied in depth [18], [19], [20], [21]. Hypervisor based and disk or storage level monitoring has been explored as well [22], [23], [24], [25], along with self healing, ransomware aware file systems [26] and data centric stopping techniques [27]. The approach in this study aims to distinguish itself by collecting data only at the storage array level and by using the hypervisor to keep the attacker unaware that it is being observed. Two studies that rely on dynamic behavior are worth discussing in more detail.
The detection system described by Kharraz et al. [28] is based on the disk access actions performed by a process. It observes the change in entropy between a read and a write to the same region of a file, the proportion of file content that is overwritten, and whether the process deletes files. It also collects metadata about disk access, including whether a process writes to many files and whether those files span very different types or come from a single application. It measures the time between write requests and assigns higher risk as that interval shortens. These features are combined into a risk score through a linear function whose weights are determined by recursive feature elimination.
In a second study, Baek et al. [24] proposed a detection model based on a set of lightweight behavioral features that describe the overwriting pattern of ransomware, a pattern that is largely invariant across families.
Figure 3. Ransomware overwriting pattern contrasted with valid applications [24].
4. Methodology
This section presents the design of the I/O pattern analyzer. By drawing on the key performance indicators present in most modern storage arrays, the detection model is independent of the operating system installed on top of the hypervisor. The design has two goals: first, to create an efficient monitoring tool, and second, to remain hidden beneath the operating system layer so that it resists ransomware evasion techniques.
4.1 Threat Model
The threat model considered in this experiment is an attacker who can infect the operating system of the virtual machine. The attacker has evaded the static detection techniques and has begun the encryption process. The attacker has no access, physical or remote, to the hypervisor. Framing the problem this way follows established threat modeling guidance for ransomware [29].
4.2 Ransomware
There are close to 400 families of ransomware. The behavioral characteristics of each family matter in the design of a detection model. The characteristics relevant to this experiment are the way the data is encrypted and the type of evasion techniques used. Other characteristics, such as the network flow and the attack vector, are outside the scope of this study.
After a certain period, a guest operating system reaches a steady state of I/O access patterns. A typical application is unlikely to behave in the same way a malicious payload does, at least not continuously. Everything a ransomware executable does requires resources such as CPU and memory, and it requires access to files, because the primary goal of a crypto locker is to encrypt all of the data in a way that makes it unusable to the victim.
I/O Access pattern
I/O Characteristics
Typical Applications
Streaming Reads
100% Reads; Large contiguous requests; 1-64 concurrent requests. It may be threaded.
Media Servers (Video-on-demand, etc.). Virtual Tape Libraries (VTL), Application Servers
Streaming Writes
100% Writes; Large contiguous requests; 1-64 concurrent requests. It may be threaded.
Media Capture, VTL, Medical Imaging, Archiving, Backup, Video Surveillance, Reference Data
OLTP
Typically, 2KB to 16KB request sizes; Read modify, write, verify operations resulting in 2 reads for every write; Primarily random accesses. Large number of concurrent requests. When running SQL statements in parallel, Database will typically perform large random I/Os.
Moderate distribution of request sizes from 4KB to 64KB. However, 4KB and 64KB comprise 70% of requests; it is primarily random; Generally, four reads for every write operation, a large number of concurrent requests during peak operational periods.
File and Printer Servers, e-mail (Exchange, Notes), Decision Support Systems
Web Server
A wide distribution of request sizes from 512 bytes to 512KB; Primarily random accesses; a Large number of concurrent requests during peak operational periods
Primarily small to medium request sizes; 80% sequential and 20% random; Generally, four reads for every writes operation. 1-4 concurrent requests.
Business Productivity, Scientific/Engineering Applications
Table 1. Application I/O characteristics by access pattern [30].
Table 1 summarizes common application types together with their typical I/O patterns and behavior. Other characteristics, such as streaming versus batch access, serial versus random access, and the block size histogram, also change during a ransomware attack. Figures 4 and 5 show examples of how data processing and access patterns differ.
Figure 4. Data processing model [30].
Figure 5. Access pattern contrast [31].
Kharraz et al. divide the characteristics of ransomware I/O access patterns into three main categories:
The attacker overwrites the user’s file with the encrypted version.
The attacker reads the file, writes a new encrypted file, and then deletes the original.
The attacker reads the file, writes a new encrypted file, and then overwrites the original.
Figure 6. I/O pattern categories according to Kharraz et al. [28].
Most families use a specific file extension for the encrypted output. For example, some Mespinoza variants of ransomware use the .pysa extension. Taking these access patterns into account, some families list and then randomly encrypt the files, which is a more advanced evasion technique. Detecting this kind of malicious behavior reliably requires several orthogonal methods of monitoring, a point expanded in the Discussion and Limitations section.
With the experimental setup ready, data collection began. A simulated ransomware script (see Appendix III) traverses the Documents folder in the Windows 10 test VM and encrypts, from top to bottom, every file with one of the following extensions:
A complete traversal of the Documents folder takes approximately seventeen minutes. Appendix IV shows a timestamped sequence of performance metric snapshots captured during a traversal.
4.3 Testbed
Configuring a laboratory setting involves several considerations. The first is to provide an environment that resembles production. In this case, several tools were used to populate a Windows 10 VM with the data needed for a ransomware attack. Building such a testbed is not trivial, and additional observations appear in the Future Work section. The design followed prudent practices for malware experiments [32], and drew on isolated analysis environments such as Cuckoo Sandbox [33], [34].
For this scenario, the operating system is assumed to be free of ransomware during the time it takes to reach steady state. That period is when the monitor reads the I/O patterns to create a clean baseline.
The operating system used for these experiments is Windows 10 Enterprise. Figure 7 shows the layout of the laboratory. The guest operating system runs on a Type 1 hypervisor, which in this case is Nutanix Acropolis. The hypervisor isolates the guest VM and prevents the ransomware from reaching anything outside the experimental environment.
Figure 7. Analysis layout with a Type 1 hypervisor.
To populate the test VM with files, two Python programs were developed to generate data. The first program, shown in Figure 8, accepts a root folder path as a starting point and creates folders to a chosen depth.
def gen_tree(depth, parent_dir):
while depth > 0:
depth = depth - 1
new_directory = random_line('words.txt')
path = os.path.join(parent_dir, new_directory)
try:
os.mkdir(path)
except OSError as error:
pass
parent_dir = path
return path
Figure 8. Python routine that creates a folder tree using common English words.
The code uses a list of the one thousand most common words in the English language [35]. According to Kharraz et al. [28], some ransomware variants compute the entropy of a file or folder name and will not trigger if the name appears too random, so realistic names matter.
For each path created, a second Python program generates Word files using the python-docx library [36]. To add images, two techniques were combined, one from Arrington [37] and one from Zita [38]. Finally, to increase the data volume, older documents were added, including PowerPoint presentations, PDF files, and additional images. Because only simulated ransomware was used, there was no risk of anyone stealing real data.
The sample data consisted of 16,447 files (see Appendix I). The final number of encrypted files was lower, approximately 12,000, because the system stalled on very large files such as .zip and .ova archives.
A second important consideration is the hardware isolation of the system in which the ransomware is triggered. Hardware isolation refers mainly to the network and to the ability of the monitoring environment to inject the ransomware without any risk of spreading it. To close network access, an isolated virtual switch with no uplink connections was used. The setup is flexible enough to move eth0 to a switch with internet access when software needs to be added to the operating system. In Figure 9, the br0 virtual switch has physical uplinks to a physical switch, while br1 is isolated.
Figure 9. Laboratory network diagram.
Because the test VMs run in a virtual environment, the console is available at any time without the risk of spreading the ransomware. With the environment and configuration described, the next section covers the key performance indicators that are available and how the data is collected.
4.4 Features
Feature identification is a broad subject. Features are the foundation of the dataset, and the dataset is only as useful as the features selected. The insight gained from the observations improves when the features chosen are well suited to the problem. This experiment had a rich set of features available; Appendix II lists them in full.
Dataset quality improves when features are selected through a formal process such as feature engineering [39]. In this case, a combination of heuristics and the findings of the research papers reviewed for this problem guided the selection. Table 2 lists the features used.
#
Selected feature
1
ctl_random_ops_per_sec
2
ctl_read_io_bandwidth_kBps
3
ctl_write_io_bandwidth_kBps
4
ctl_num_read_iops
5
ctl_num_write_iops
6
hv_avg_read_io_latency_usecs
7
hv_avg_write_io_latency_usecs
8
ctl_total_read_io_size_kbytes
9
ctl_read_size_histogram_4kB
10
ctl_read_size_histogram_8kB
11
ctl_read_size_histogram_16kB
12
ctl_read_size_histogram_32kB
13
ctl_read_size_histogram_64kB
14
ctl_read_size_histogram_512kB
15
ctl_read_size_histogram_1024kB
16
ctl_write_size_histogram_4kB
17
ctl_write_size_histogram_8kB
18
ctl_write_size_histogram_16kB
19
ctl_write_size_histogram_32kB
20
ctl_write_size_histogram_64kB
21
ctl_write_size_histogram_512kB
22
ctl_write_size_histogram_1024kB
Table 2. Features selected for the detection model.
The intuition behind this selection is that, during a ransomware attack, the I/O statistics rise above their normal levels and the characteristics of the steady state I/O pattern change. The two clearest signals were the block size and the randomness of access. For a complete list of candidate features, see Appendix II.
4.5 Dataset
A dataset is a collection of data samples. The dataset in this experiment contains measurements collected every 120 seconds through a REST API. There are several ways to collect this data, as shown in Figure 10. A REST API request was chosen because the results can be written to a comma separated value (.csv) file for use in training. Most modern storage arrays expose the same measurements, so the results apply to enterprises of any size without vendor lock in.
Figure 10. Monitoring tools for the Nutanix Acropolis cluster.
Figure 10 shows Prism, the built in monitoring tool, which includes I/O and network flow monitoring. The hyperconverged system provides an HTML5 user interface, a REST API, and a command line utility. The experiment assumes that the operating system, in this case Windows 10 Enterprise, has reached a steady state I/O pattern and is free of any ransomware infection.
When building a machine learning dataset, the ground truth data is split into a training dataset and a testing dataset. The algorithm is trained on the training data and then evaluated on its ability to perform on the testing data [40].
Figure 11. REST API access to the Nutanix data platform [41].
To retrieve the performance indicators, the Nutanix cluster is queried with a request that includes:
the unique identifier of the virtual disk (UUID);
the metric, or KPI, being requested;
the start time and end time in microseconds, using the 24 hour Unix epoch format; and
the interval in seconds, where the minimum for this version of Nutanix is 120 seconds.
Appendix V contains the code used to retrieve the KPI through the REST API.
One of the main challenges in behavioral detection is distinguishing a valid application from an actual ransomware attack. Some families go further and become adversarial by using several evasion techniques. One technique that would make this approach less robust [42] is for the malware to observe its environment and imitate normal behavior.
To model a valid application workload, the experiment used DISKSPD, a command line tool for micro benchmarking [43], [44]. The following options were used:
This command runs a 30 second random I/O test against a 20 GB file on the C: drive, with a 25 percent write and 75 percent read ratio and an 8 KB block size. It uses eight worker threads, each with four outstanding I/Os, and a write entropy seed of 1 GB, and it saves the results to a text file. The equivalent utility on Linux is fio [45], [46].
The DISKSPD emulator was used to model a SQL database as a representative application workload. The Future Work section returns to the need to model many suitable applications in order to build a more robust model.
5. Analysis
With the data collected (see Appendix VI for an example), it must be prepared before it can train the model. Two columns were added. The first is a VM identifier, which keeps the model ready for future experiments with additional test VMs. The second is the target metric, a column that indicates whether the data was collected during a ransomware attack. The value is zero for a normal operating system and one for an operating system under a ransomware attack. The word controller was shortened to ctl_, because the dataset import process appears to limit the length of a feature name and the characters it can contain.
5.1 Azure Machine Learning
There are two ways to apply Azure Machine Learning here. In the first, the collected data trains a model that classifies an operating system as either clean or infected. This is a binary classification problem, which can use Azure Automated Machine Learning. In the second, the collected data serves as a baseline and Azure Anomaly Detection identifies departures from it. Open source workbenches such as WEKA [47] offer comparable modeling capabilities, but a managed cloud service keeps the workflow accessible without local setup [48].
5.2 Automated Machine Learning
Automated machine learning, also called automated ML or AutoML, automates the time consuming, iterative tasks of model development. It lets data scientists, analysts, and developers build models at scale with efficiency and productivity while preserving model quality [49]. The automated workflow used here was as follows:
A .csv file with the collected data was uploaded. The data includes the I/O information of the test VM both with and without ransomware [50].
The target metric for the classification is the Ranso column.
Azure Automated ML evaluated several algorithms, trained the corresponding models, and recommended the best model based on accuracy. This process is time consuming.
The recommended pipeline used MaxAbsScaler with a random forest [51].
The data was flagged as imbalanced, most likely because there were far more samples without ransomware than with it.
Automated ML ran for close to an hour and recommended a random forest (Figures 12 and 13).
Figure 12. Top ranked algorithms reported by Azure Automated ML.
Figure 13. Lowest ranked algorithms reported by Azure Automated ML.
Figure 14. Supervised learning pipeline using a two class decision forest.
In Figure 14, the trained model uses the two class decision forest. The steps are:
upload the .csv to create a dataset, in this case Win10WithRanso;
normalize the data using min and max scaling;
split the data into 70 percent for training and 30 percent for evaluation;
train a model using the two class decision forest algorithm; and
score and evaluate the model (see the Findings section for details).
At this point there is a trained model that can detect at least the type of ransomware in which encryption proceeds by reading, overwriting, and renaming the file. Because there are many families of ransomware, broader coverage would require additional models.
5.3 Azure Anomaly Detection
Because a ransomware event is not common, collecting data about it is difficult, and by the nature of malicious activity the datasets are imbalanced. To handle imbalanced data, Azure Machine Learning provides a category called anomaly detection.
The collected data fits that category well: it is numerical data gathered as a uniformly spaced time series. Azure ML can detect trends and spikes and report the changes as anomaly scores. It uses principal component analysis (PCA), a technique often used in exploratory data analysis because it reveals the inner structure of the data and explains its variance [52].
Figure 15. Learning pipeline for the anomaly detection approach.
Once the model is trained with data collected while the operating system has no ransomware, future KPI readings can be evaluated through a deployed API. The Python code below tests the model with new data, and the JSON sample that follows shows the source KPI data.
Figure 16. Python source used to query the anomaly model.
[
{
"VM": 1,
"ctl_random_ops_per_sec": 612,
"ctl_read_io_bandwidth_kBps": 3438,
"ctl_write_io_bandwidth_kBps": 1187,
"ctl_num_read_iops": 428,
"ctl_num_write_iops": 145,
"hv_avg_read_io_latency_usecs": 0,
"hv_avg_write_io_latency_usecs": 0,
"ctl_total_read_io_size_kbytes": 412656,
"ctl_read_size_histogram_4kB": 0,
"ctl_read_size_histogram_8kB": 41125,
"ctl_read_size_histogram_16kB": 0,
"ctl_read_size_histogram_32kB": 43,
"ctl_read_size_histogram_64kB": 0,
"ctl_read_size_histogram_512kB": 0,
"ctl_read_size_histogram_1024kB": 0,
"ctl_write_size_histogram_4kB": 127,
"ctl_write_size_histogram_8kB": 13831,
"ctl_write_size_histogram_16kB": 5,
"ctl_write_size_histogram_32kB": 13,
"ctl_write_size_histogram_64kB": 8,
"ctl_write_size_histogram_512kB": 0,
"ctl_write_size_histogram_1024kB": 1280,
"Ranso": 0
},
Figure 17. Sample JSON file with source KPI data.
6. Findings
This section interprets the data and points to directions for further research. The results are presented with a confusion matrix, the standard way to evaluate a classification model [53]. In these matrices, cases where both the predicted and actual values are one (true positives) appear at the top left, and cases where both the predicted and actual values are zero (true negatives) appear at the bottom right.
Data was collected for two ransomware encryption events. The first dataset contained 1,441 rows collected while the operating system was normal and nine rows collected during encryption. Azure Machine Learning trained the model by splitting the data into 70 percent for training and 30 percent for evaluation. Figure 18 shows the results.
Figure 18. Confusion matrix for the first run.
As Figure 18 shows, the model produced a 100 percent true positive rate, and on only one occasion it predicted no encryption while encryption was in progress. In a second, fully independent experiment, the model was retrained using 63 rows collected during encryption. This time the output was 100 percent true positives and 100 percent true negatives, as shown in Figure 19.
Figure 19. Confusion matrix for the second run.
The more actions that are considered, and the more of them that are present during ransomware activity, the higher the identification rate. Collecting all of these actions, however, requires letting the ransomware run freely long enough to encrypt and destroy many files. In these experiments, the ransomware encrypted approximately seven hundred files per minute.
A second model was configured with Azure anomaly detection. For ransomware encryption, it identified the anomaly in 100 percent of cases. The anomaly model was trained on data from the operating system without ransomware. Table 3 shows the output of the anomaly model on the collected data.
Ranso
Scored Label
Probability
1
1
0.938535
1
1
0.927582
1
1
0.923774
1
1
0.93596
1
1
0.914103
1
1
0.930306
1
1
0.911739
1
1
0.938852
1
1
0.761196
1
1
0.938535
1
1
0.927582
1
1
0.923774
1
1
0.93596
1
1
0.914103
1
1
0.930306
1
1
0.911739
1
1
0.938852
1
1
0.761196
1
1
0.938535
1
1
0.927582
1
1
0.923774
1
1
0.93596
1
1
0.914103
1
1
0.930306
1
1
0.911739
1
1
0.938852
1
1
0.761196
1
1
0.938535
1
1
0.927582
1
1
0.923774
1
1
0.93596
1
1
0.914103
1
1
0.930306
1
1
0.911739
1
1
0.938852
1
1
0.761196
1
1
0.938535
1
1
0.927582
1
1
0.923774
1
1
0.93596
1
1
0.914103
1
1
0.930306
1
1
0.911739
1
1
0.938852
1
1
0.761196
1
1
0.938535
1
1
0.927582
1
1
0.923774
1
1
0.93596
1
1
0.914103
1
1
0.930306
1
1
0.911739
1
1
0.938852
1
1
0.761196
1
1
0.938535
1
1
0.927582
1
1
0.923774
1
1
0.93596
1
1
0.914103
1
1
0.930306
1
1
0.911739
1
1
0.938852
1
1
0.761196
Table 3. Output of the anomaly model on the collected data.
The decision threshold can be tuned between zero and one; the default is 0.5. In this experiment the lowest certainty probability was 0.76, which stayed well above the default threshold.
7. Discussion and Limitations
Both trained models, the binary classifier and the anomaly detector, effectively detect an attack. Once detection occurs, rapid response techniques and good operational practices can support recovery. A short script can take a snapshot of the system as soon as an anomaly is detected, and on most modern storage arrays a snapshot does not affect performance.
After several weeks of research, reading, and testing, a number of limitations of this approach became clear:
The model was trained on the behavior of one specific VM, so it is not a generic model. Addressing this would require an automated training process that builds one model per VM.
Collecting data from a VM that is in production is difficult. In the laboratory it was possible to infect the test VM and take it down to collect data, but a production approach would need to clone the production VM, infect the clone, aggregate the data from both the production VM and the infected clone into a dataset, train and deploy the model, and then periodically update the model by repeating those steps.
The number of observations in these experiments is small. To confirm the encouraging early findings, the observations and the collected data should be extended to many operating systems running multiple workloads.
For the two reasons above, the anomaly detector is likely a better choice than the two class algorithm.
8. Future Work
This section offers a few ideas for stronger protection and higher detection accuracy. Rather than relying on a single way to detect ransomware after the static defenses have been defeated, the proposal is to combine several subsystems that together form a layered defense around the environment:
I/O to the storage array. This is the approach presented in this study. It would be worth adding both per VM and total storage array performance, since that combination did not appear in the reviewed material.
File decoys. A honey file technique helps to reduce false positive results [54], [55].
Compression and deduplication. Both measurements drop during encryption, because encrypted files are poor candidates for compression and deduplication. The idea is promising, although by the time the change is visible it may be too late to stop the encryption.
Backup verification. Most attacks try to stop the backup system; the challenge is that backup systems vary from one environment to another.
Network communication. This signal supports the overall strategy and is very effective when combined with the other layers.
There is also a newer way to consume storage in a virtualized environment. The underlying storage is divided into chunks using virtual volumes (VVols) [56]. As the limitations show, it would help for the system to be aware of the specific files the ransomware accesses. Correlating file metadata with VVol utilization could give the model more insight and raise confidence in detection.
Figure 20. Proposed system for future work.
In Figure 20, the proposed system has two dynamic behavior monitors on the left. When an anomaly occurs, the message queue receives the alert. The top right shows a backup process monitor, and the lower right shows the honey file, or canary file, check. The bottom center shows the two outputs for a positive ransomware detection: on the left, the process that snapshots the system, and on the right, the alert module.
Acknowledgments
I thank my family for their support and patience during this research. I also thank Dr. Mustaque Ahamad for his guidance during the semester; his feedback and recommendations helped me meet the learning objectives of the course. Finally, I thank my fellow students, whose positive attitude and strong work in the weekly progress reports kept motivation high.
Appendix
Appendix I. File Extension Detailed Count
The sample dataset used to exercise the simulated ransomware contained the file types listed below, grouped by extension with total size and file count.
File Extension
Total Size(Mb)
File Count
Total
107.846
421
.al
0.672
1
.at
0.053
2
.backup
0.121
2
.bak
34.416
7
.basex
0.007
10
.bash_history
0.01
1
.bashrc
0.003
1
.bat
0.035
17
.bin
3.099
6
.boot
0
1
.bz2
0.832
1
.c
2.46
27
.c32
0.338
4
.cat
0.706
5
.cfg
0.288
6
.changed
0
1
.class
1.942
794
.clb
0.046
2
.com
0.121
1
.common
0.005
1
.conf
0.69
6
.config
0.087
3
.controlio
0.172
5
.cpgz
24.645
1
.cpp
0.029
1
.crash
0.024
1
.crdownload
292.116
3
.crit
0
1
.css
0.141
43
.csv
3.082
114
.ctd
0.009
4
.ctx
0.575
5
.db
0.406
1
.deb
57.375
5
.debug
0.176
4
.default
0
1
.der
0.001
1
.dir
0.034
1
.diskdefines
0
1
.dll
0.787
2
.dmg
88.35
3
.doc
15.569
32
.docm
0.316
2
.docx
518.988
486
.dotx
0.398
3
.drt
0.776
1
.dtd
0.088
3
.dump
0.031
2
.dylib
0.073
2
.EFI
2.367
2
.eml
0.053
2
.ena
0.46
3
.ent
0.029
3
.eps
14.637
17
.epub
5.389
1
.err
0.019
6
.exe
2074.402
27
.factoryio
0.386
3
.FCD
0
4
.flake8
0.001
1
.gif
0.119
43
.gpg
5.252
3
.grp
20.764
2
.gz
1374.106
205
.h
0.06
5
.hpp
0.008
1
.htc
0.002
2
.htm
0.028
3
.html
5.557
25
.icns
0.249
2
.ico
0.049
2
.ics
0.019
6
.img
9.604
5
.in
0
1
.info
0
2
.ini
0.002
7
.input_i
0.312
2
.iso
20275.221
16
.jar
156.356
342
.jnlp
0.056
15
.jpeg
3.906
18
.jpg
157.814
162
.jpg_large
0.325
1
.js
4.105
106
.json
24.039
164
.kdb
0.008
4
.kdbx
0.038
13
.keystream
0.855
3
.kit
0.033
2
.lbb
0.279
3
.len
0
7
.lic
0.209
93
.license
0.001
1
.lock
0
1
.log
204.64
302
.lst
0.01
8
.manifest
0.071
3
.md
0.053
15
.md5
0
2
.mgmtd
0.71
1
.mod
2.012
236
.mp4
493.219
1
.mpp
0.133
1
.msg
0.092
1
.msi
125.717
7
.names
0.004
1
.nar
107.019
32
.ndp-proxy
0.006
1
.netconfig
0.011
1
.netrwhist
0
1
.nib
0.346
22
.notice
0
1
.nvram
0.071
1
.old
1881.357
11
.omsg
0.084
1
.one
0.836
1
.out
31.379
27
.ova
20349.079
9
.pak
92.225
2
.pcap
0.003
1
.pcf
0.001
2
.pdf
1264.323
1457
.pem
0.003
2
.pf2
0.005
1
.pfx
0.002
1
.pg_dump
0.017
1
.pkg
16.106
2
.plist
0.005
2
.png
108.406
1415
.policy
0.013
1
.potx
5.945
1
.ppt
34.654
4
.pptx
529.425
171
.profile
0
1
.properties
0.024
8
.psd
1.427
10
.pxd
0.005
3
.py
6.193
647
.pyc
0.54
63
.pyd
4.313
16
.pyi
0.463
184
.pyx
0.085
3
.rar
5.278
1
.rdp
0.011
6
.rll
1.357
1
.rpc
0.041
2
.rpm
1764.365
27
.rpm-utils
0.002
1
.rsrc
0.001
1
.rtf
1.823
102
.run
140.476
1
.s
0.018
2
.sample
0.02
12
.sb
1987.047
2
.SET
0.037
3
.sh
223.587
20
.SHData
0.295
12
.size
0
1
.slf
0.007
7
.so
12.772
59
.sql
0.004
1
.sqlite
1.125
1
.st
0.013
9
.strings
0
2
.symbolMap
50.915
6
.sys
0.066
1
.tar
933.62
15
.template
1.885
8
.tex
0
1
.tgz
1520.12
27
.thrift
0.001
1
.tif
2.037
3
.tiff
5.499
75
.TORRENT
0.018
1
.ts
0.221
14
.ttf
3.288
21
.txt
91.105
567
.url
0
1
.vdx
8.448
7
.vib
103.035
6
.viminfo
0.011
1
.vmdk
26319.876
4
.vmsd
0
2
.vmsn
0.028
1
.vmx
0.006
2
.vmxf
0.004
2
.vscodeignore
0.001
41
.vsd
116.928
50
.vsdx
11.482
14
.vss
216.994
13
.vssx
5.846
2
.war
3.833
2
.warn
0
2
.x32
0.199
1
.x64
0.2
1
.xls
64.106
203
.xlsm
98.673
121
.xlsx
242.441
415
.xml
70.862
4454
.xq
8.21
1735
.xqm
0.196
31
.xsd
0.122
20
.xslt
0.001
2
.yml
0.001
1
.zip
16207.155
232
Appendix II. Available Features
The Nutanix platform exposes the performance indicators below at the VM, cluster, and storage container levels. The subset used for the model appears in Table 2.
VM
Cluster
Storage Container
CPU Usage (%)
CPU Usage (%)
Storage Controller IOPS (IOPS)
CPU Ready Time (%)
Memory Usage (%)
Storage Controller Read IOPS (IOPS)
Memory Usage (%)
Controller IOPS (IOPS)
Storage Controller Write IOPS (IOPS)
Storage Controller IOPS (IOPS)
Controller Read IOPS (IOPS)
Storage Controller Latency (ms)
Storage Controller Read IOPS (IOPS)
Controller Write IOPS (IOPS)
Storage Controller Read Latency (ms)
Storage Controller Write IOPS (IOPS)
Controller AVG Latency (ms)
Storage Controller Write Latency (ms)
Storage Controller Latency (ms)
Controller AVG Read Latency (ms)
Storage Controller I/O Bandwidth (Mbps)
Storage Controller Read Latency (ms)
Controller AVG Write Latency (ms)
Storage Controller Read Bandwidth (Mbps)
Storage Controller Write Latency (ms)
Controller I/O Bandwidth (Mbps)
Storage Controller Write Bandwidth (Mbps)
Storage Controller I/O Bandwidth (Mbps)
Controller Read Bandwidth (Mbps)
Storage Controller Read Bandwidth (Mbps)
Controller Write Bandwidth (Mbps)
Storage Controller Write Bandwidth (Mbps)
Disk Usage (GiB)
Virtual Disk
Disk Usage (%)
Random I/O (%)
Snapshot Usage (GiB)
Read Source Cache (KBps)
Shared Data (GiB)
Read Working Set size (MiB)
I/O Working Set size (MiB)
Write Working Set size (MiB)
Read I/O Working Set size (MiB)
Union Working Set Size
Write I/O Working Set size (MiB)
Read Size Distribution (bytes/%)
Write Size Distribution (bytes/%)
Network Receive Packets Dropped (# packets)
Network Transmit Packets Dropped (# packets)
Network Rx (KiB)
Network Tx (KiB)
Appendix III. Simulated Ransomware Script (Python)
The script below traverses a target folder and, for each file whose extension matches the encryption list, encrypts the file in place using a symmetric key. It was used only against the isolated test VM, and the equivalent PowerShell technique is described by Rayner [57].
importos
fromcryptography.fernetimportFernet
defencrypt_file(filename):
# process one file here
#Generate a key
key=Fernet.generate_key()
#Save the key to the file my_key.key
withopen('my_key.key','wb')asmy_key:
my_key.write(key)
# Initialize fernet object
fernet_object=Fernet(key)
# Read the file
withopen(filename,'rb')asoriginal_file:
original=original_file.read()
# Encrypt the file
encrypted=fernet_object.encrypt(original)
# Overwrite the file
try:
withopen(filename,'wb')asencrypted_file:
encrypted_file.write(encrypted)
except:
pass
defdecrypt_file(filename):
# Read the key from the file "my_key.key"
withopen('my_key.key','rb')asmy_key:
key=my_key.read()
# Initialize fernet object
fernet_object=Fernet(key)
# Read the encrypted file
withopen(filename,'rb')asencrypted_file:
encrypted=encrypted_file.read()
# Decrypt the file
decrypted=fernet_object.decrypt(encrypted)
# Overwrite the file
withopen(filename,'wb')asdecrypted_file:
decrypted_file.write(decrypted)
defget_file_list(root_folder):
file_list=[]
# for root, dirs, files in os.walk(root_folder, topdown=False): #to list bottom-up
# To decrypt: uncomment lines 65 and 70 and comment lines 72 and 78
forfile_nameinfile_list:
decrypt_file(file_name)
print(file_name.split('.'))
#os.rename(file_name, file_name.split('.pysa')
'''
else:
print("Folder does not exist")
Appendix IV. Sequence of Graphical Data During Ransomware Encryption
The snapshots below show the Prism performance metrics captured at successive timestamps while the simulated ransomware encrypted the Documents folder.
Figure A4.1. Performance metrics snapshot 1 of 9 during encryption.
Figure A4.2. Performance metrics snapshot 2 of 9 during encryption.
Figure A4.3. Performance metrics snapshot 3 of 9 during encryption.
Figure A4.4. Performance metrics snapshot 4 of 9 during encryption.
Figure A4.5. Performance metrics snapshot 5 of 9 during encryption.
Figure A4.6. Performance metrics snapshot 6 of 9 during encryption.
Figure A4.7. Performance metrics snapshot 7 of 9 during encryption.
Figure A4.8. Performance metrics snapshot 8 of 9 during encryption.
Figure A4.9. Performance metrics snapshot 9 of 9 during encryption.
Appendix V. Python Code to Retrieve KPI Using the REST API
import pprint
import json
import os
import random
import time
import requests
import sys
import traceback
# This block initializes the parameters for the request.
class AHVRestApi():
def __init__(self):
# Initializes the options and the logfile from GFLAGS.
self.serverIpAddress = "NUTANIX SERVER IP ADDRESS"
self.username = "USERNAME"
self.password = "PASSWORD"
# Base URL at which REST services are hosted in Prism Gateway.
[5] G. Hull, H. John, and B. Arief, “Ransomware deployment methods and analysis: Views from a predictive model and human responses,” Crime Science, vol. 8, no. 2, 2019, doi: 10.1186/s40163-019-0097-9.
[6] E. Berrueta, D. Morato, E. Magana, and M. Izal, “A survey on detection techniques for cryptographic ransomware,” IEEE Access, vol. 7, pp. 144925-144944, 2019, doi: 10.1109/ACCESS.2019.2945839.
[8] M. S. Abbasi, H. Al-Sahaf, and I. Welch, “Particle swarm optimization: A wrapper-based feature selection method for ransomware detection and classification,” in Applications of Evolutionary Computation (EvoApplications 2020), Lecture Notes in Computer Science, vol. 12104. Cham, Switzerland: Springer, 2020, pp. 181-196, doi: 10.1007/978-3-030-43722-0_12.
[9] O. M. K. Alhawi, J. Baldwin, and A. Dehghantanha, “Leveraging machine learning techniques for Windows ransomware network traffic detection,” in Cyber Threat Intelligence, Advances in Information Security, vol. 70. Cham, Switzerland: Springer, 2018, pp. 93-106, doi: 10.1007/978-3-319-73951-9_5.
[10] R. Moussaileb, N. Cuppens, J.-L. Lanet, and H. Le Bouder, “Ransomware network traffic analysis for pre-encryption alert,” in Foundations and Practice of Security (FPS 2019), Lecture Notes in Computer Science, vol. 12056. Cham, Switzerland: Springer, 2020, pp. 20-38, doi: 10.1007/978-3-030-45371-8_2.
[11] G. Cusack, O. Michel, and E. Keller, “Machine learning-based detection of ransomware using SDN,” in Proc. 2018 ACM Int. Workshop on Security in Software Defined Networks & Network Function Virtualization (SDN-NFV Sec), 2018, pp. 1-6, doi: 10.1145/3180465.3180467.
[12] H. Daku, P. Zavarsky, and Y. Malik, “Behavioral-based classification and identification of ransomware variants using machine learning,” in Proc. 2018 17th IEEE Int. Conf. Trust, Security and Privacy in Computing and Communications / 12th IEEE Int. Conf. Big Data Science and Engineering (TrustCom/BigDataSE), 2018, pp. 1560-1564, doi: 10.1109/TrustCom/BigDataSE.2018.00224.
[13] S. K. Shaukat and V. J. Ribeiro, “RansomWall: A layered defense system against cryptographic ransomware attacks using machine learning,” in Proc. 2018 10th Int. Conf. Communication Systems & Networks (COMSNETS), 2018, pp. 356-363, doi: 10.1109/COMSNETS.2018.8328219.
[14] G. Ramesh and A. Menen, “Automated dynamic approach for detecting ransomware using finite-state machine,” Decision Support Systems, vol. 138, art. 113400, 2020, doi: 10.1016/j.dss.2020.113400.
[15] B. A. S. Al-rimy, M. A. Maarof, and S. Z. M. Shaid, “Ransomware threat success factors, taxonomy, and countermeasures: A survey and research directions,” Computers & Security, vol. 74, pp. 144-166, 2018, doi: 10.1016/j.cose.2018.01.001.
[16] D. W. Fernando, N. Komninos, and T. Chen, “A study on the evolution of ransomware detection using machine learning and deep learning techniques,” IoT, vol. 1, no. 2, pp. 551-604, 2020, doi: 10.3390/iot1020030.
[17] O. Or-Meir, N. Nissim, Y. Elovici, and L. Rokach, “Dynamic malware analysis in the modern era: a state of the art survey,” ACM Computing Surveys, vol. 52, no. 5, art. 88, pp. 1-48, 2019, doi: 10.1145/3329786.
[18] A. Mohaisen, O. Alrawi, and M. Mohaisen, “AMAL: High-fidelity, behavior-based automated malware analysis and classification,” Computers & Security, vol. 52, pp. 251-266, 2015, doi: 10.1016/j.cose.2015.04.001.
[19] D. Sgandurra, L. Munoz-Gonzalez, R. Mohsen, and E. C. Lupu, “Automated dynamic analysis of ransomware: Benefits, limitations and use for detection,” arXiv:1609.03020, Sep. 2016.
[20] M. E. Ahmed, H. Kim, S. Camtepe, and S. Nepal, “Peeler: Profiling kernel-level events to detect ransomware,” in Computer Security: ESORICS 2021, Lecture Notes in Computer Science, vol. 12972. Cham, Switzerland: Springer, 2021, pp. 240-260, doi: 10.1007/978-3-030-88418-5_12.
[21] A. Y. Huang, “Towards robust malware detection,” M.Eng. thesis, Dept. Electr. Eng. Comput. Sci., Massachusetts Inst. Technol., Cambridge, MA, USA, 2018.
[22] A. Fattori, A. Lanzi, D. Balzarotti, and E. Kirda, “Hypervisor-based malware protection with AccessMiner,” Computers & Security, vol. 52, pp. 33-50, 2015, doi: 10.1016/j.cose.2015.03.007.
[23] N. Paul, S. Gurumurthi, and D. Evans, “Towards disk-level malware detection,” in Proc. Workshop on Code Based Software Security Assessments (CoBaSSA), 2005.
[24] S. Baek, Y. Jung, A. Mohaisen, S. Lee, and D. Nyang, “SSD-Insider: Internal defense of solid-state drive against ransomware with perfect data recovery,” in Proc. 2018 IEEE 38th Int. Conf. Distributed Computing Systems (ICDCS), 2018, pp. 875-884, doi: 10.1109/ICDCS.2018.00089.
[25] W. Xie, N. Chen, and B. Chen, “Poster: Incorporating malware detection into flash translation layer,” in Proc. 2020 IEEE Symp. Security and Privacy (Poster Session), 2020.
[26] A. Continella, A. Guagnelli, G. Zingaro, G. De Pasquale, A. Barenghi, S. Zanero, and F. Maggi, “ShieldFS: A self-healing, ransomware-aware filesystem,” in Proc. 32nd Annu. Computer Security Applications Conf. (ACSAC), 2016, pp. 336-347, doi: 10.1145/2991079.2991110.
[27] N. Scaife, H. Carter, P. Traynor, and K. R. B. Butler, “CryptoLock (and drop it): Stopping ransomware attacks on user data,” in Proc. 2016 IEEE 36th Int. Conf. Distributed Computing Systems (ICDCS), 2016, pp. 303-312, doi: 10.1109/ICDCS.2016.46.
[28] A. Kharraz, W. Robertson, D. Balzarotti, L. Bilge, and E. Kirda, “Cutting the Gordian knot: A look under the hood of ransomware attacks,” in Detection of Intrusions and Malware, and Vulnerability Assessment (DIMVA 2015), Lecture Notes in Computer Science, vol. 9148. Cham, Switzerland: Springer, 2015, pp. 3-24, doi: 10.1007/978-3-319-20550-2_1.
[29] D. Sebayan, “How threat modeling can prevent your next ransomware attack,” ThreatModeler, 2019. [Online]. Available: https://threatmodeler.com/
[32] C. Rossow, C. J. Dietrich, C. Grier, C. Kreibich, V. Paxson, N. Pohlmann, H. Bos, and M. van Steen, “Prudent practices for designing malware experiments: Status quo and outlook,” in Proc. 2012 IEEE Symp. Security and Privacy, 2012, pp. 65-79, doi: 10.1109/SP.2012.14.
[47] G. Holmes, A. Donkin, and I. H. Witten, “WEKA: A machine learning workbench,” in Proc. 2nd Australia and New Zealand Conf. Intelligent Information Systems (ANZIIS), 1994, pp. 357-361.
[54] C. Moore, “Detecting ransomware with honeypot techniques,” in Proc. 2016 Cybersecurity and Cyberforensics Conf. (CCC), 2016, pp. 77-81, doi: 10.1109/CCC.2016.14.
For years, Nutanix was almost synonymous with HCI, where compute and storage live together in the same nodes. That model works exceptionally well for general-purpose workloads, but it has always had a ceiling: when you need more storage capacity or performance, you also have to buy more compute, whether you need it or not.
The formal partnership between Nutanix and Pure Storage, announced at .NEXT 2025 in May, changes that equation. Nutanix AHV can now run as a compute only platform backed by Pure Storage FlashArray over NVMe/TCP. Each Nutanix AOS vDisk maps directly to a FlashArray volume, which means per VM granularity for snapshots, quality-of-service controls, and replication. You get the operational simplicity of Prism as a unified management plane while the FlashArray handles the storage heavy lifting underneath.
This post walks through what it actually takes to build that environment, based on the Cisco FlashStack with Nutanix Installation Field Guide (v1.0, December 2025) and supplemental information from Nutanix and Pure Storage documentation.
Architecture Overview
The deployment model covered here uses Cisco UCS servers (X-series, C-series, or B-series) as compute only nodes, managed by Cisco Intersight in Intersight Managed Mode (IMM). The nodes connect to Cisco UCS Fabric Interconnects (FIs), and those FIs connect upstream to top of rack switches. The Pure Storage FlashArray sits off to the side as a dedicated external storage array, connected to those same ToR switches over NVMe/TCP.
No local storage is used for AOS datastores. The nodes are diskless or have local drives used only for the hypervisor boot.
Storage traffic travels over dedicated VLANs and dedicated vNIC pairs, separate from management and guest VM traffic.
The Nutanix Controller VM (CVM) on each node handles the NVMe/TCP initiator connections to the FlashArray automatically. Administrators do not need to manually configure NVMe initiators.
Prism Central (or Prism Element) is the primary management interface for the cluster, while Cisco Intersight manages the UCS hardware layer.
Software Version Requirements
Before any hardware gets racked, confirm that all components meet the minimum software versions. Using mismatched versions is one of the most common causes of failed deployments.
Component
Minimum Version
Notes
Nutanix AOS
7.5 or later
Nutanix AHV
11.0 or later
Foundation Central
1.10 only
Do not use 2.x at this time
Prism Central
7.5 or later
Required for Licensing
Nutanix LCM
3.3
Included with AOS 7.5
Pure Storage Purity/FA
6.10.3 or later
Upgrade must be done before installation begins
Cisco Fabric Interconnect
4.3(4.240066) or later
Cisco Intersight Virtual Appliance
1.1.5-1 or later
Older CVA/PVA versions will cause failures
Cisco UCS X210c-M7 Firmware
5.4(0.250048) or later
Cisco UCS C-series M6/M7 Firmware
4.3(6.250053) or later
Cisco UCS B-series M5/M6 Firmware
5.3(0.250021) or later
Important: Only Foundation Central version 1.10 should be used. The Appliance VM version 2.x is explicitly not supported for this deployment type. Do not use it.
IP Address Planning
IP address planning should be completed before any configuration begins. Retrofitting addressing after the fact wastes time and introduces risk.
Infrastructure
2 addresses for the Fabric Interconnects
1 address for the Foundation Central Appliance VM
1 optional address for Prism Central / Foundation Central VM
Per Nutanix Host (five addresses each)
AHV hypervisor management address
Controller VM (CVM) management address
CIMC management address (assigned as a pool in Intersight)
Storage interface address, VLAN 1 (assigned as a pool in Prism Element)
Storage interface address, VLAN 2 (assigned as a pool in Prism Element)
Pure Storage FlashArray (seven addresses)
1 per controller management interface
1 roaming array management address
1 per NVMe/TCP storage interface (minimum 4 across two controllers and two VLANs)
Storage addresses must be Layer 2 adjacent to the hosts and cannot traverse a router. Use two separate storage VLANs, one for the A side controller interfaces and one for the B side.
Step 1: Pure Storage FlashArray Configuration
The FlashArray setup is best done via CLI. Some configuration tasks cannot be completed through the Purity GUI. This assumes the array is already racked, cabled, powered on, and reachable on its management network, with Purity/FA 6.10.3 or later already running.
Enable and Configure NVMe/TCP Interfaces
Four Ethernet interfaces need to be assigned to NVMe/TCP. The example below uses interfaces eth10 and eth11 on each controller.
# Enable the four storage interfaces
purenetwork eth enable ct0.eth10
purenetwork eth enable ct0.eth11
purenetwork eth enable ct1.eth10
purenetwork eth enable ct1.eth11
# Assign addresses, MTU 9000, and NVMe/TCP service
purenetwork eth setattr --address 10.1.61.100/24 --mtu 9000 --servicelist nvme-tcp ct0.eth10
purenetwork eth setattr --address 10.1.62.100/24 --mtu 9000 --servicelist nvme-tcp ct0.eth11
purenetwork eth setattr --address 10.1.61.101/24 --mtu 9000 --servicelist nvme-tcp ct1.eth10
purenetwork eth setattr --address 10.1.62.101/24 --mtu 9000 --servicelist nvme-tcp ct1.eth11
Use MTU 9000 (jumbo frames) wherever possible. If jumbo frames are not supported end to end in your network, set MTU to 1500 and ensure consistency across all components.
Create the Realm, Pod, and Administrative User
# Create the Realm for RBAC segmentation
purerealm create <realm_name>
# Create a Pod within the Realm for this Nutanix cluster
purepod create <realm_name>::<pod_name>
# Create the management access policy granting admin rights to the Realm
Important: Set a storage quota on the Pod after creation. Without a quota, the array will not accurately report available storage to Nutanix.
Step 2: Cisco UCS and Intersight Configuration
Configure Fabric Interconnect A first via serial console or HTTPS Express Setup, setting the management mode to Intersight. After FI-A shows a login prompt, configure FI-B. FI-B will detect the peer and prompt to join the cluster.
Once the FIs are up, log into Cisco Intersight and claim the UCS domain using the Device ID and Claim Code from the FI web console. Create Resource Groups and an Organization, create and deploy a Domain Profile to the Fabric Interconnects, and set the System QoS Best Effort MTU to 9216 to allow jumbo frames.
This is where compute only Nutanix deployments require careful attention. Each server needs at least two vNIC pairs: an infrastructure pair for AHV and CVM management traffic, and a dedicated storage pair carrying the NVMe/TCP storage VLANs.
Infrastructure vNIC naming is case sensitive. Foundation Central will reject the deployment if these names are wrong. For a single VIC server use ntnx-infra-1-A on Slot MLOM, PCIe Order 0, Fabric A, Failover disabled and ntnx-infra-1-B on Slot MLOM, PCIe Order 1, Fabric B, Failover disabled.
Step 3: Foundation Central Deployment
For first-time cluster deployments with no existing Nutanix infrastructure, the Appliance VM is the simplest path. Deploy it with 2 vCPUs and 4 GB RAM with a static IP address. DHCP is not supported. Run the setup script from the local console after booting and access the GUI at https://<FC_IP>:9440.
Upload the AOS installation package, its metadata JSON file, and the AHV ISO via API calls to the Appliance VM. Retrieve the hosted file URLs by browsing to http://<FC_IP>:8053/files/images and enter those URLs into the cluster deployment wizard.
Step 4: Nutanix Cluster Deployment
Connect Foundation Central to Cisco Intersight by entering the API Key ID and Secret Key under Settings. The API key user must have at minimum Server Administrator privileges in the relevant Intersight Organization.
Onboard the Cisco UCS servers by selecting Intersight Managed Mode and choosing the target nodes
Select the onboarded nodes and click Create Cluster
Select Compute Cluster (not HCI Cluster, since there is no local storage)
Configure the infrastructure vNIC pair and at least one dedicated storage vNIC pair
Assign IP addresses and hostnames. Use Bulk Configuration to set sequential addresses efficiently
Enter the download URLs for AOS, the AOS metadata file, and the AHV ISO
Set NTP servers, DNS servers, and timezone
Select the Foundation Central API Key and click Create Deployment
Deployments without firmware changes typically complete in 75 to 90 minutes. If firmware upgrades are required, add 60 to 90 minutes.
Step 5: External Storage Connectivity
After the Nutanix cluster is up and accessible in Prism Element, select I’ll Do This Later when prompted to set up external storage. The virtual switch configuration must be done first.
Edit the default virtual switch vs0 to remove any storage vNICs, leaving only the infrastructure vNIC pairs as uplinks
Create a new dedicated storage virtual switch, assign it the storage vNIC pair, set MTU to 9000, and Bond Type to Active-Active with MAC pinning
Create one External Storage Interface per storage VLAN, associated with the new storage virtual switch, with an IP pool large enough for one address per node plus room for growth. Enable the External Storage option and set MTU to 9000.
Before attaching the array, verify jumbo frame connectivity from the CVMs to all four FlashArray storage interfaces:
ping -M do -s 8972 10.1.61.100
ping -M do -s 8972 10.1.62.100
ping -M do -s 8972 10.1.61.101
ping -M do -s 8972 10.1.62.101
All four tests should complete with 0% packet loss. From Prism Element, click Attach External Storage, select Pure Storage FlashArray, enter the clustered management IP, the Realm administrative username and password, select the Realm and Pod, and click Attach. The connection typically completes within 30 to 60 seconds.
Step 6: Post-Installation Tasks
Change the default passwords on three accounts on AHV (root, admin, and nutanix) and on the CVM nutanix account. Run the NCC password health check after: ncc health_checks system_checks default_password_check
Run a full NCC health check from Prism Element and resolve all failures and warnings before the cluster goes into production. LCM 3.3 ships with AOS 7.5. Run an inventory job to see available Nutanix software updates. Note that LCM will not perform server firmware updates for compute only nodes connected to external storage.
Things Worth Calling Out
vNIC naming. The ntnx-infra-1-A and ntnx-infra-1-B names in the LAN Connectivity Policy are case sensitive. A single capitalization error will cause the deployment to fail at validation. Fix it in the Intersight policy and resubmit.
Foundation Central version. Version 1.10 only. The Appliance VM version 2.x exists and is available, but it does not work with Cisco UCS hardware in this context. Do not use it.
Jumbo frames. The MTU 9000 setting at the vNIC level and the virtual switch level only permits jumbo frames to pass; it does not enforce them. All switching infrastructure between the hosts and the FlashArray interfaces must also support 9000 byte frames. Use the ping test above to verify before attaching the array.
Storage VLAN design. Use two separate storage VLANs, one for the A side controller interfaces and one for the B side. Storage addresses within each VLAN must be in the same Layer 2 domain as the hosts and cannot be routed.
Pod quota. Without setting a storage quota on the Pure Storage Pod, Nutanix will not accurately display available storage capacity. Set it immediately after verifying the Realm and Pod are created.
Summary
The Nutanix AHV compute only model backed by Pure Storage FlashArray over NVMe/TCP represents a meaningful shift in how converged infrastructure is deployed. It separates the scaling concerns for compute and storage, delivers per VM storage granularity at the array level, and maintains a single management plane through Prism for day to day operations.
The installation process involves more moving parts than a traditional HCI cluster. Cisco Intersight, Foundation Central, Purity CLI, and Prism Element all play distinct roles, and the sequencing matters. Following the steps in order and confirming each layer before moving to the next is the most reliable path to a successful deployment.
For questions about this architecture or assistance planning a deployment, reach out at javier.rodriguez@eplus.com.
Every VMware to Nutanix AHV migration project comes with the same fundamental tension: you want to move workloads to a better platform without disrupting the people who depend on those workloads every day. The good news is that Nutanix Move, when paired with a well defined phased methodology, handles that tension well. This post walks through how we approach these engagements at ePlus, covering the migration mechanics, database specific considerations, and the operational steps that close out each phase cleanly.
How Nutanix Move Works
Nutanix Move is a cross hypervisor mobility tool that automates VM migrations from VMware ESXi, Hyper-V, or public cloud sources to Nutanix AHV. The core model is straightforward: Seed, Sync, Cutover.
Discovery: Connect Move to the source environment (vCenter, standalone ESXi, or Hyper-V) and the target Nutanix cluster. Move inventories the VMs and validates compatibility before anything touches production data.
Data Seeding: Move creates a placeholder VM on the AHV side and begins copying virtual disks from the source. This initial seed runs in the background while the source VM stays live.
Changed Block Tracking (CBT): After the initial copy, Move uses CBT to replicate only blocks that have changed since the last sync. This keeps the replication delta small and the eventual cutover window short.
Why Daytime Replication Is Safe
A common concern when planning migrations is whether running replication during business hours will hurt production performance. In practice, it does not, and here is why.
Non Disruptive Snapshots Move uses native snapshot mechanisms (VMware CBT, for example) to read source data. The VM stays powered on and users experience no interruption.
Network Throttling Move supports bandwidth throttling on migration traffic so replication does not compete with production traffic on shared links during peak hours.
Background Operation The seeding phase is a background task. End users are fully isolated from the process because their application is still running on the source hypervisor.
Incremental Efficiency After the initial seed, subsequent syncs only move changed blocks, so the bandwidth consumption of ongoing replication is a fraction of the initial transfer.
The Cutover Process
The cutover is the only step that involves any downtime, and even that window is typically measured in minutes per VM. The sequence is deterministic and should be documented in the project plan before any work begins.
Final Sync: Move performs one last incremental sync to capture the most recent changed blocks.
Graceful Shutdown: The source VM is powered off cleanly, not forcefully terminated.
Final Delta: A final incremental pass captures any blocks written during the shutdown sequence.
Activation: Move installs the required VirtIO drivers for AHV, optionally reconfigures IP addressing, and powers the VM on within the Nutanix cluster.
Practical Note For most general purpose VMs, the combined downtime from final sync through power on on AHV is under five minutes. Database VMs with large in flight transactions may take slightly longer depending on the final delta size.
Rollback Strategy
One of the most important things to communicate to stakeholders before a cutover is that rollback is not a complex recovery procedure. It is simply reversing a power state.
Because Move does not delete or modify the source VM during cutover (it only powers it off and disconnects its network interface), the path back to the original state requires no data restoration. If a migrated VM does not perform as expected on AHV, the steps are:
Power off the VM on the Nutanix AHV side.
Reconnect the network interface on the source VM.
Power on the source VM in the original environment.
The source disks remain completely untouched throughout the process, so this rollback takes seconds rather than hours. It also means stakeholder sign off on a cutover carries much lower risk than it would in a traditional migration approach.
Special Migration Scenarios
Not every VM is a candidate for a straightforward Move migration. A few categories require a different approach:
Legacy Operating Systems: Windows Server 2003 and older Linux kernels with unsupported kernel versions are explicitly unsupported by modern versions of Nutanix Move and the standard AHV VirtIO driver set. These workloads cannot use the standard Move migration path and require an alternative approach such as a cold clone, a bare metal backup restoration, or an application level migration to a newly provisioned VM.
Physical Hardware Pass through: VMs with PCI pass through devices or Raw Device Mappings (RDMs) require manual reconfiguration on the target side.
Shared Disk Clustering: Certain older Oracle RAC or MSCS configurations that rely on shared SCSI bus emulation need architectural review before migration.
For these cases, the alternatives range from a manual cold clone, to an application level migration, to a fresh OS installation with data restoration from backup. The right path depends on the workload, and that decision should be made during technical discovery before the project schedule is finalized.
Database Migration Methodology
Databases deserve a separate treatment because the consequences of a failed migration, or even a migration that succeeds but lands on a poorly configured target, are higher than for stateless application servers. We cover both Microsoft SQL Server and Oracle here.
Storage Architecture for Database VMs
Nutanix gives database workloads two primary storage paths: native vDisks and Nutanix Volume Groups.
Native vDisks are the default for AHV VMs and are simple to manage through Prism. Starting with AOS 6.x, the Autonomous Extent Store (AES) improved local sharding for native vDisks, so they are no longer as constrained as they were in earlier releases. That said, a single CVM still serves as the primary I/O path for a given vDisk, which means very high throughput workloads can reach a performance ceiling at the CVM level.
Nutanix Volume Groups (VG) are collections of vDisks presented as block devices. For AHV, VGs can be direct attached, appearing as native SCSI devices to the guest OS. When Volume Group Load Balancing (VGLB) is enabled, the system shards vDisks across all CVMs, removing the single CVM I/O path and allowing the database to draw on the aggregate throughput of the entire cluster’s Stargate processes.
iSER Support: For the highest performance requirements, Nutanix supports iSER (iSCSI Extensions for RDMA), which bypasses the TCP/IP stack entirely to reduce latency and CPU overhead between the guest and the CVM. This is worth evaluating for latency sensitive OLTP workloads.
AHV Specific Tuning for Databases
Several AHV configuration decisions have a direct and measurable impact on database performance.
vCPU to pCPU Ratio: For production databases, size assuming 1 vCPU equals 1 physical core, not one hyperthreaded thread. Oversubscription introduces CPU Ready Time, which is particularly harmful to latency sensitive query workloads. Target below 5% CPU Ready.
Memory Reservations: Reserve 100% of assigned VM memory for SQL Server and Oracle VMs. AHV memory reclamation through ballooning or swapping can cause significant and hard to diagnose latency spikes in database workloads.
Huge Pages: AHV uses 2 MB Huge Pages to reduce Translation Lookaside Buffer (TLB) pressure. Ensure the guest OS is configured to use large page allocations to take advantage of this.
vNUMA: For VMs larger than a single physical socket, enable vNUMA and match the virtual topology to the physical hardware. This allows the database engine to schedule threads and memory access with NUMA awareness. Disable CPU hot add, as enabling it disables vNUMA and can cause performance degradation of up to 30%.
AOS Features That Matter for Databases
Data Locality AOS stores a VM’s data on the same physical node where the VM runs. Read I/O is served locally without network traversal, which reduces database read latency materially.
AHV Turbo (Frodo I/O Path) Bypasses traditional QEMU emulation with a multi-queue I/O path that scales with the number of vCPUs, delivering higher I/O capacity and lower CPU overhead for storage intensive workloads.
Nutanix Blockstore A block management system that moves device interactions into user space, eliminating context switching and kernel driver overhead for data disks.
VGLB for OLAP Volume Group Load Balancing distributes I/O across all CVMs in the cluster. Critical for high throughput OLAP and reporting workloads that can saturate a single CVM.
Microsoft SQL Server Migration Options
There are three viable paths for SQL Server migrations, and the right choice depends on the deployment type and the acceptable downtime window.
Nutanix Move: The simplest path for standalone instances. Move handles disk conversion to AHV RAW format, VirtIO driver injection, and IP configuration. Best suited for standalone instances where a brief cutover window is acceptable.
Always On Availability Groups: Build a new SQL VM on AHV, join it to the existing Windows Server Failover Cluster (WSFC), and add it as a new secondary AG replica. Once synchronized, perform a planned manual failover to promote the Nutanix based node, then decommission the old nodes. This approach reduces cutover risk for business critical SQL workloads and can achieve near zero application downtime.
Backup and Restore: Take a full backup of the source database, restore it on a pre staged SQL VM on AHV using WITH NORECOVERY, and during the cutover window take a tail log backup, restore it with WITH RECOVERY, and redirect applications to the new instance.
Oracle Migration Options
Nutanix Move: Recommended for migrating the Oracle VM as is from vSphere to AHV when the VM itself is in Move’s compatibility matrix. Move handles VirtIO driver injection automatically.
RMAN Active Duplication: Use Oracle Recovery Manager to perform an active duplication from the source to a new Oracle VM on AHV. The source database remains online until the final switchover, minimizing the downtime window.
Data Guard: Set up a physical standby on the Nutanix cluster, synchronize it via RMAN, and then perform a Data Guard switchover to promote the Nutanix instance to primary. This is the lowest risk option for Oracle databases with strict RPO/RTO requirements.
Oracle RAC with Nutanix Volumes: For RAC deployments, Nutanix Volumes provide the shared block storage required by clusterware. Volume Groups should be attached via iSCSI and configured with SCSI-3 Persistent Reservations.
SQL Server Best Practices on AHV
These configurations should be treated as baseline for any production SQL Server on Nutanix, whether migrated or newly deployed.
Storage Layout
Use at least four vDisks to distribute data files, log files, TempDB, and the OS independently.
Format all data and log volumes with a 64 KB NTFS allocation unit size.
Do not use Windows Dynamic Disks or in guest volume managers. Add vDisks directly to the VM instead.
Keep OS, SQL binaries, user database data, logs, and TempDB on separate volumes.
Instance Level Tuning
Instant File Initialization (IFI): Grant the SQL Server service account the “Perform Volume Maintenance Tasks” privilege to enable IFI. This eliminates zero initialization overhead during data file creation and auto growth events. IFI applies only to data files (.mdf and .ndf). Log files (.ldf) are always zero initialized regardless of this setting. Starting with SQL Server 2016, IFI can also be enabled directly from the installation wizard.
Lock Pages in Memory (LPIM): Enable LPIM to prevent Windows from paging the SQL Server buffer pool to disk. Max Server Memory must be set correctly before enabling LPIM to avoid starving the guest OS.
Max Server Memory: For mid to large VMs, leave 6 to 8 GB for the OS. For VMs under 32 GB of RAM, 4 GB is often sufficient. A practical formula: reserve 10% of total RAM for the OS, with a ceiling of around 8 GB unless SSIS or SSRS also run on the same instance.
MAXDOP: Set MAXDOP to the number of logical cores within a single vNUMA node. For SQL Server 2016 and later, the updated guidance is to use either 8 or the number of cores per NUMA node, whichever is smaller.
Cost Threshold for Parallelism (CTFP): Increase from the default of 5 to at least 50. OLTP workloads land at 50. Hybrid environments sometimes use a value in the 25 to 50 range.
TempDB: Match the number of data files to the logical processor count when that count is 8 or fewer. Start at 8 data files when the logical processor count exceeds 8. Only increase beyond 8 (in increments of 4) if PAGELATCH_UP or PAGELATCH_SH waits confirm actual contention.
SQL Server Baseline Configuration Summary
Setting
Recommended Baseline
Reason
IFI
Enabled
Eliminates zero initialization overhead for data files during creation and auto growth.
LPIM
Enabled
Prevents Windows from reclaiming the SQL Server buffer pool. Requires Max Server Memory to be set first.
Max Server Memory
Total RAM minus 4 to 8 GB (or 10% of total RAM)
Prevents SQL Server from starving the guest OS.
MAXDOP
8 or cores per NUMA node, whichever is smaller
Keeps parallel query execution within a single NUMA domain.
CTFP
50 (or 25 to 50 for hybrid workloads)
Prevents low cost queries from triggering parallelism on modern multi core hardware.
TempDB
Match logical processor count up to 8; increase by 4 only when contention is confirmed
Reduces allocation contention. All files must be equally sized with identical growth settings.
Oracle Best Practices on AHV
Oracle on Nutanix AHV benefits from the same platform level advantages as any other workload, but the database engine has enough specific tuning requirements that it warrants its own treatment.
Memory Allocation: SGA and PGA
Reserve approximately 10 percent of the total VM memory for the guest OS and file cache. Of the remaining 90 percent, allocate 80 percent to the System Global Area (SGA) and the remaining 20 percent to the Program Global Area (PGA). Memory reservations should be set to 100% of the assigned VM memory. Memory overcommit is not recommended for Oracle workloads.
Storage Layout and Disk Groups
NDB provisions multiple vDisks spread across ASM disk groups to maximize throughput across the Distributed Storage Fabric. The two primary disk groups are DATADG for database data files and RECODG for redo logs and archive files. For Oracle RAC, a third disk group CRSDG is required for Grid Infrastructure and clusterware files.
Disk Group
Small or Medium (500 GB and under)
Large (501 GB and above)
CRSDG (RAC only)
3 vDisks
3 vDisks
DATADG
4 vDisks
8 vDisks
RECODG
2 vDisks
4 vDisks
ASM Configuration Options
Nutanix supports ASMFD (ASM Filter Driver), ASMLIB, and udev rules for ASM disk mappings. ASMFD is the preferred method on modern Linux distributions. All ASM disks should be placed on vDisks in an AOS storage container with inline compression enabled and deduplication disabled.
Network Design for Oracle RAC
Oracle RAC requires a public network for client connections and a private interconnect for cache fusion on separate VLANs. Mixing them on the same VLAN introduces the risk of cache fusion traffic competing with client traffic. When using NDB to provision Oracle RAC, NDB manages IP address assignment across public, private, and virtual (scan and VIP) network types.
RAC and Nutanix Volumes: Oracle RAC requires shared storage for the CRSDG disk group. On AHV, this is provided through Nutanix Volume Groups attached via iSCSI with SCSI-3 Persistent Reservations enabled. This is a prerequisite for RAC clusterware to function correctly.
Oracle Patching with NDB
NDB uses an out of place patching model for Oracle. Rather than patching a running Oracle home directly, the process involves provisioning a new database VM from an existing software profile, manually applying the patch set to that VM, and then creating a new software profile version from the patched VM. Once published, that version becomes available to all Oracle VMs managed by NDB. Patching can be performed in either a rolling or non rolling fashion for Oracle RAC environments.
Time Machine Backup and Recovery for Oracle
NDB Time Machine creates application consistent snapshots of Oracle databases along with copies of transaction log files. An SLA attached to the time machine controls snapshot frequency and retention. Point in time recovery is available as long as both a base snapshot and the covering transaction logs exist for the target timestamp. NDB restores the vDisks from the appropriate snapshot and then applies log files forward to bring the database to a consistent state.
Decommissioning Protocol
The migration is not complete when the VM powers on successfully on AHV. A structured decommissioning process ensures the legacy environment is cleaned up safely.
Step
Action
Owner
1
Source VMs remain powered off with NIC disconnected for a 48 to 72 hour burn in period to prevent IP conflicts.
Infrastructure Team
2
Confirm with Application Owners that performance and stability on AHV is acceptable after the burn in period.
Project Lead
3
Archive a final backup of the source VM according to the organization’s retention policy before deletion.
Backup Admin
4
Remove the VM from the source cluster inventory.
Infrastructure Team
5
Update the CMDB or asset tracker to reflect the VM’s new hypervisor and decommission the legacy record.
IT Operations
Technical Discovery Requirements
The quality of the discovery work done before migration determines how smooth everything else goes. At a minimum, the following information should be gathered before any migration plan is finalized.
General Infrastructure
Specific vSphere version and ESXi build number in use on source hosts
Networking configuration: LACP, Jumbo Frames (MTU 9000), or standard configuration
IP retention requirement: retain existing IPs after migration or assign new IPs on AHV
Guest OS list with versions and BIOS/UEFI boot mode for each VM in scope
SQL Server Environments
SQL Server versions and editions (Standard vs. Enterprise) deployed
Deployment type: Standalone, Failover Cluster Instance (FCI), or Always On AG
Current vCPU to physical core allocation and whether LPIM is already configured
vDisk layout per VM: number of disks, purpose (Data, Log, TempDB), and whether any single large data files exist that should be split
Dependencies on MSDTC, Linked Servers, or SQL Agent Jobs that require documentation before cutover
Oracle Environments
Oracle versions in scope and whether instances are Single Instance or RAC
Shared storage configuration for RAC: ASM with ASMLib, ASMFD, or udev rules
Huge Pages configuration status in the guest OS
Existing RMAN backup workflows or Data Guard standbys that can be leveraged
Source platform architecture: if any workloads currently run on AIX or Solaris (SPARC), be aware that Nutanix Move is strictly an x86-to-x86 tool and cannot be used for these migrations. AIX and Solaris on SPARC are Big-Endian, while Nutanix AHV runs exclusively on x86-64 (Little-Endian). Cross-endian migrations require a fully manual path using RMAN CONVERT for Oracle or an application level export and restore, and should be scoped separately from the rest of the Move migration plan.
Migration Constraints
Maximum acceptable maintenance window for final cutover
Average daily change rate for production databases (drives seeding bandwidth planning)
Top 10 application functions or queries to validate Day 1 performance after migration
Total allocated versus used storage per database environment, plus expected annual growth
Every VCF deployment starts the same way: someone hands you a blank whiteboard and says design it. The problem is that VCF 9.1 is a broad platform, and without a structured approach it is easy to make decisions out of order, miss dependencies, or find out three phases in that an early choice locked you into something you did not intend.
Broadcom organizes the VCF 9.1 design process into nine phases covering 31 distinct decisions. This post walks through each phase, what the decisions are, and why they matter in practice. If you are using the VCF Designer tool, this maps directly to the decision schema it uses.
Phase 1: Starting Point and Profile
Before touching any configuration, you need two things nailed down: the design blueprint and the scope.
The Design Blueprint is your baseline deployment profile. Broadcom defines several: single site minimal, single site, multi-site single region, multi-region, and others covering application and security modernization. This is not a technical decision as much as it is a business one. It defines the complexity ceiling for everything that follows.
Scope and Use Cases is where you gate the rest of the design. VCF 9.1 can cover private cloud IaaS, Kubernetes via Supervisor, Private AI Foundation, vDefend lateral security, VCF Edge, and disaster recovery. What you check here enables or disables options in later phases. Do not mark something in scope unless there is a real requirement behind it.
Phase 2: Fleet-Level Decisions
The VCF Fleet Deployment Model defines how the fleet is laid out. A single VCF instance is the most common for customers starting out or running a standalone private cloud. A connected fleet with multiple instances comes into play when you have multiple sites or organizational boundaries that require separate management planes.
The VCF Fleet Sizing Model covers appliance sizing: Small, Medium, HA Medium, Large, and HA Large. Sizing here is not about your workload VMs. It is about the management plane itself. Undersizing the fleet appliances is one of the most common mistakes in early VCF deployments.
Phase 3: Consumption Decisions
This phase covers how cloud consumers interact with the platform. Five decisions, and they are tightly interconnected.
The VCF Automation Model decides whether VCF Automation is deployed and in what topology. If your organization needs self-service provisioning or catalog-driven deployments, you need this. If not, skip it. Running it just because it is available adds operational overhead without benefit.
The Network Consumption Model is one of the most consequential decisions in the entire design. VLAN, NSX Overlay Segments, VPC, or Transit Gateway. This drives downstream decisions on edge clusters, load balancers, and how workloads connect. Get this wrong and you are rearchitecting the network mid-project.
Workload Connectivity and Load Balancer Model follow from the network consumption choice. For load balancing, NSX Native covers most use cases. Avi (VCF Advanced LB) is needed when you require full L7 with advanced policies, SSL offload, or WAF capabilities.
Phase 4: Operations Decisions
Six decisions covering management services, management networking, operations tooling, logging, network observability, and recovery.
The VCF Management Services Model defines availability for SDDC Manager, vCenter, and NSX Manager. Standard vs. Highly Available. For production environments, the answer is almost always HA. The cost of an HA management plane is small compared to the cost of a failed SDDC Manager during a critical operation.
The VCF Management Network Model determines whether management components share a VLAN, use isolated VLANs per component, or run on NSX segments. NSX segments require NSX to be up before management components can communicate, which creates a chicken-and-egg risk during recovery scenarios. Plan this carefully.
The VCF Recovery Option aligns to your RPO and RTO requirements. Backup and restore, component-level recovery, and instance-level recovery each have different complexity and cost profiles. Define your recovery requirements before choosing this, not after.
Phase 5: Security and Compliance
Identity Broker and SSO decisions define how users authenticate to VCF components. Most enterprise environments will federate to Active Directory or an external IdP. Plan this early since it affects every component that needs authentication.
vDefend Lateral Security only applies if it was included in scope in Phase 1. If deployed, the Security Services Platform adds distributed IDS/IPS and east-west traffic inspection.
Phase 6: Virtual Infrastructure
Seven decisions covering domains, clusters, networking, and storage. This is where the design gets concrete.
The VCF Domain Model defines your management and workload domain topology. Single-AZ with one management plus one workload domain is the most common starting point. Stretched (multi-AZ) adds complexity but is required for metro HA.
The Storage Model is one of the decisions with the most downstream impact. VCF 9.1 supports vSAN OSA, vSAN ESA, NFS, VMFS on Fibre Channel, iSCSI, and NVMe variants. vSAN ESA is the recommended path for new deployments using compatible hardware. If you are connecting to an existing SAN or NAS, the external storage options apply.
NSX Manager topology and NSX Edge Cluster decisions define the control plane and data plane for your overlay network. Edge cluster sizing depends on the volume and type of north-south traffic. A shared NSX Manager cluster across domains reduces overhead. Dedicated per domain gives you blast radius isolation.
Phase 7: Physical Infrastructure
One decision: the Network Fabric Model. Routed VLAN fabric, Leaf-Spine VXLAN underlay, or EVPN-VXLAN fabric. This needs to be made in coordination with the network team. The fabric model affects how VLANs are extended across the environment and how the NSX overlay integrates with the underlay. EVPN-VXLAN provides the most flexibility for multi-site and stretched cluster scenarios.
Phase 8: Optional Workload Capabilities
VCF Edge and Private AI Foundation, both conditional on Phase 1 scope. For VCF Edge, single-host is suitable for small remote sites where HA is not required. Three-host provides local HA at the edge.
For Private AI Foundation, the compute model selection depends heavily on the type of workloads. Training workloads typically want full GPU passthrough or MIG. Inference workloads can often share via vGPU.
Phase 9: Closeout
Two workflow tasks, not configuration decisions. First, reconcile every decision made in Phases 1 through 8 against the Broadcom VCF Design Library to confirm alignment with supported patterns. Second, translate the finalized design into the VCF Planning and Preparation Workbook, which is the actual input consumed by the VCF Installer during bring-up. A clean design that does not translate into a properly completed workbook will cause bring-up failures. Budget time for this step.
My work life as an IT specialist has always been quite varied.
I spent part of my time installing traditional datacenter infrastructure, some of my time implementing cybersecurity solutions, and bits and pieces here and there, working on projects with a number of different technology vendors.
But over the past 18 months, my main focus has been: migrate customers’ virtualization environments to Nutanix.
The timing lines up with some big shakeups in the tech industry, as well as the continued growth of hyperconverged infrastructure (HCI). I heard my customers worry that support quality would decline for their existing environments, or that innovation might stall. In reality, what my customers have mostly seen is severe sticker shock on their renewal bills—partly due to inflation that has hit all sectors, but also due to dramatic changes to vendor licensing agreements.
Some customers have seen 3x, 5x, or even 10x increases in their virtualization costs, practically overnight. These are customers that have been with a vendor for 15 or 20 years, in many cases, and many had come to view their virtualization environments as something of a commodity with a stable pricing structure. But changes to licensing agreements have upended this stability. Before, customers could mostly purchase individual product licenses as needed, but they’re now being funneled into bundled packages with add-on features they don’t want and can’t use.
Some large enterprises are able to absorb these new costs. But for others—especially small and medium-sized companies—the impact to their business is comparable to tripling their rent, or adding a zero to their monthly utility bills. These smaller customers also find themselves in a poor negotiating position with tech giants.
For example, we recently worked with Norfolk Public Schools in Virginia to migrate to Nutanix. The district was facing an eye-popping 680% cost increase if it stayed with its previous provider, but a five-year licensing agreement saved it approximately $2 million.
For customers like Norfolk Public School, the numbers of the new virtualization landscape simply don’t add up. And for the first time, many of these organizations are willing to seriously consider a change.
Even non-technical people can understand the anxiety that comes with switching technology platforms. (Think of how rarely people change to a phone with a different operating system.) Most of my customers never even considered switching from their existing virtualization provider until recently. After all, virtualization is a foundational technology that supports their entire business. Many system administrators have built their careers and expertise around the environment they know, developed their own workflows around its interface and capabilities, and integrated their entire application environment with that platform.
Most importantly, businesses have come to rely on the stability of their virtualization environments to keep their mission-critical systems up and running. So, it’s understandable why many approach a change with a degree of trepidation. They want to know whether their applications will work the same way, how much downtime to expect, and whether their teams will need extensive retraining.
However, once customers make the move, they tend to find that Nutanix infrastructure provides everything they need—and often in a more intuitive way, at what essentially amounts to what they were paying before the market shifts of the past couple off years. During the pre-sales process, I sit with customers to walk them through the Nutanix interface. We spend much of this time exploring the equivalent functionality between the platforms, which is often mostly a matter of learning new terminology for familiar features.
At Norfolk Public Schools, we conducted site assessments, installed and configured new hardware, configured the Nutanix platform, and migrated more than 400 virtual machines—all in just over a month. The cutover to the new operating environment was seamless, and the district saw immediate improvements in performance and reliability.
For most organizations, the migration is just as painless. Some clients prefer to migrate in small batches of just a few virtual machines, while others are ready to move hundreds of virtual machines over a single weekend. The actual cutover process for each virtual machine takes only about five to ten minutes—comparable to the standard maintenance window for most security patches. Post-migration, customers typically notice improved performance (mostly due to new hardware). In addition to the cost savings, many also cite Nutanix’s simplified disaster recovery capabilities as a major benefit of the move.
After we start the migration, I can see the anxiety on my customers’ faces melt away, replaced by relief. Recently, one even started laughing. “This is so amazing!” he kept repeating. “This is so easy!”
In this comprehensive guide, we demystify the process of cloning a Linux operating system (Ubuntu) and guide you through the intricacies of booting directly from an iSCSI LUN. We’ll walk you through the entire process, from selecting the right tools for cloning to configuring your system for iSCSI boot. Whether you’re a seasoned Linux administrator or a curious enthusiast, this step-by-step guide is tailored to empower you with the knowledge and skills needed to successfully clone and boot Linux from an iSCSI LUN.
Let’s begin with a summary of the technology prerequisites for accomplishing this task. Firstly, you’ll require a Linux box, whether physical or virtual. It’s essential to note that the method I propose involves system downtime, so scheduling a maintenance window is advisable, particularly if your system is in production. As part of this approach, a connection between the source system and the target Volume/LUN is crucial. I’ll explore the concept of cloning to a file from the source and transporting it to the target side in a future post.
Lastly, a target system capable of providing the iSCSI volume is indispensable for the successful execution of this process. Keep these key components in mind as we delve into the steps for cloning a Linux OS and booting from an iSCSI LUN in our detailed guide.
If you want to Lab the cloning, you’ll need three things:
Linux Box: I will be using Ubuntu, you can download Ubuntu here: https://ubuntu.com/
root@lab-vm:/home/lab# cat /etc/fstab # /etc/fstab: static file system information. # # Use 'blkid' to print the universally unique identifier for a # device; this may be used with UUID= as a more robust way to name devices # that works even if disks are added and removed. See fstab(5). # # <file system> <mount point> <type> <options> <dump> <pass> # / was on /dev/sda2 during curtin installation /dev/disk/by-uuid/91cf8b5a-2c4d-49c4-bcb5-57b59339a2c0 / ext4 defaults 0 1 /swap.img none swap sw 0 0
Based on the results of the earlier commands, we’ve identified that our system is installed directly on /dev/sda. With this understanding, let’s proceed to boot Linux from a Live Ubuntu ISO Image and open a Terminal window. See the following slideshow of the process:
While in the live Ubuntu you could enable ssh to make everything easier. From the terminal executed the following commands
sudo su
apt install openssh-server -y
systemctl enable ssh
ufw allow ssh
I already have my Nutanix CE deployed and an iSCSI lun configured. The Discovery IP address in my case is 192.168.1.51 and the name on the iSCSI Lun is iqn.2010-06.com.nutanix:lab-boot-lun-ee392c61-6958-4be2-88fc-636bed265e09. To configure the Lice Ubuntu to access the Lun execute these commands (while logged with root using ‘sudo su’):
In my case the original drive is in /dev/sda and the new iSCSI lun is /dev/sdb, to start the cloning execute the following command: dd if=/dev/sda of=/dev/sdb bs=32M status=progress
The next step must be done before the reboot. It will configure the system to boot from the new iSCSI Lun.
And you should have a system booting from the iSCSI Lun. In case that you don’t have access to both the source and target drives, you can pipe the dd command to gzip and save it to a file that can be read at the target system. An example is:
dd if=/dev/sda | gzip > file.gz
I hope you find this post useful and remember to have a good backup before attempting the cloning procedure.
This is the second post in a series about the new CCNA DevNet certification (Previous Post Here). In this post, we will look at how to manage in Python the three formats that we previously discussed.
Example of XML parsing in Python
from __future__ import print_function
import xml.etree.ElementTree as ET
def main():
# create element tree object
with open('xmlfile.xml', 'r') as xmlFile:
tree = ET.parse(xmlFile)
# get root element
root = tree.getroot()
print("Root Tag: " + root.tag)
print("Using a for Loop:")
for child in root:
print(child.tag)
for attrib in child:
print(attrib.tag, end=' ')
print(attrib.text)
print("Using Indexes:")
print(root[0].tag)
print(root[0][0].tag,end=' ')
print(root[0][0].text)
print(root[0][1].tag,end=' ')
print(root[0][1].text)
print(root[1].tag)
print(root[1][0].tag,end=' ')
print(root[1][0].text)
print(root[1][1].tag,end=' ')
print(root[1][1].text)
print(root[2].tag)
print(root[2][0].tag,end=' ')
print(root[2][0].text)
print(root[2][1].tag,end=' ')
print(root[2][1].text)
print("Other:")
for hostname in root.iter('hostname'):
print(hostname.tag,end=' ')
print(hostname.text)
if __name__ == "__main__":
# calling main function
main()
To achieve something similar with the .json file we would use “import json”
import json
def main():
with open('jason.json', 'r') as jsonFile:
#load jason file
myJasonFile = json.load(jsonFile)
print(myJasonFile)
if __name__ == "__main__":
# calling main function
main()
And to parse YAML
import yaml
with open("yamlfile.yaml", 'r') as yamlFile:
try:
print(yaml.safe_load(yamlFile))
except yaml.YAMLError as exc:
print(exc)
VMworld 2017 General Session Day Two
Tue, 29 Aug 2017 17:44:05 +0000
https://vwannabe.com/2017/08/29/vmworld-2017-general-session-day-two/
The CISCO Blueprint uses REST calls to a site and parses the JSON. You can find the example here. In the next port for this series, I will talk about “Describe the concepts of test-driven development”.
I will start a series of posts on the new CCNA DevNet certification. I will keep my SOP of going through the curriculum and google the concepts for you. I will try to include Youtube videos of some of the topics that have more hands-on exercises. The certification name is Cisco Certified DevNet Associate. The first topic if about software development and design. It includes some essential topics that I synthesize in the rest of this post.
1.0 Software Development and Design – Compare data formats (XML, JSON, YAML)
The formats XML, JSON, and YAML are data-serialization formats, from Wikipedia: In computer science, in the context of data storage, serialization (or serialisation) is the process of translating data structures or object state into a format that can be stored (for example, in a file or memory buffer) or transmitted (for example, across a network connection link) and reconstructed later (possibly in a different computer environment). When the resulting series of bits is reread according to the serialization format, it can be used to create a semantically identical clone of the original object.
Mostly you will probably accomplish your task with any of the three. If you are a javascript developer, you will probably feel more comfortable with JSON (JavaScript Object Notation), or if you code in Python, you might stick to YAML (YAML Ain’t Markup Language). The XML (eXtensible Markup Language) format comes from the World Wide Web Consortium (W3C).
One difference between them is the format used by each. The XML uses tags like HTML, JSON uses objects in attribute-value pairs, and YAML uses indentation like Python.
Here is a JSON snippet that I use as part of the Cisco HyperFlex Installation.
The previous example means that I have something called “esx”, which is the Hypervisor, and that I have three of them (XX1-XX3). Each has an IP address and a hostname. In XML it should like this:
It is recommended to use the builtin libraries and not make your own to avoid mistakes. For example, javascript uses the JSON.parse() method, and python uses the JSON library. Example of use of the JSON library:








![Figure 1. Steps in ransomware activity [6].](https://i0.wp.com/vwannabe.com/wp-content/uploads/2026/06/fig01_ransomware_steps.jpg?resize=467%2C79&ssl=1)
![Figure 2. The legacy three tier infrastructure consists of three layers: the compute layer, the storage area network or fabric (SAN), and the storage array or arrays [7].](https://i0.wp.com/vwannabe.com/wp-content/uploads/2026/06/fig02_hci_vs_three_tier.jpg?resize=512%2C257&ssl=1)