Explain When a hardware based application deliver platform solution is appropriate
(Explain the purpose, advantages, and challenges associated with hardware based application deliver platform solutions)
BIG-IP 8950 & 11050 Hardware Helps Customers Meet Growing Throughput Demands
- The new platforms support high throughput levels to meet the application delivery needs of service providers and organizations that put a premium on transactions per second, such as financial institutions. The BIG-IP 8950 platform features a throughput level of 20 Gbps, while the 11050 boasts 42 Gbps.
- The solutions support 10 Gb Ethernet connectivity to help bandwidth-conscious customers deliver enhanced application services. The platforms provide ideal solutions for customers that have configured their data centers around 10GE or are currently planning to upgrade their infrastructure.
- With the 8950 and 11050 platforms, customers have the ability to incorporate additional application services (acceleration, high availability, application security, etc.), as their business needs evolve. Because these capabilities can be added to the existing ADN hardware platform, F5 solutions offer both enhanced functionality and optimum performance.
Explain when a virtual machine solution is appropriate
(Explain the purpose, advantages, and challenges associated with virtual machines)
BIG-IP LTM VE Improves ADC Scalability and Simplifies Solution Deployment
- Virtual ADCs can be rapidly deployed and scaled to support applications as resources are needed. In addition, cloud providers can leverage virtual ADCs to apply specific application policies on a per customer basis to support individual organizations’ business priorities.
- BIG-IP LTM VE provides improved evaluation, development, integration, QA, and staging for application delivery policies and deployments. By enabling customers to deploy a virtual BIG-IP device in a testing lab, customers can conveniently test how applications and networks will respond in a production environment. This capability also enables customers to evaluate the addition of other ADC services such as SSL offloading, caching, and compression, and seamlessly transfer from testing scenarios into production.
- BIG-IP LTM VE will be available in a full production version and a non-production lab version, as well as the previously announced trial. The full production version features variable throughput options up to 1Gbps. The lab version enables in-depth testing, and is best suited for efforts around application development, test, QA, and other non-production scenarios.
- Unlike other virtualized application delivery offerings, BIG-IP LTM VE is part of a comprehensive application delivery architecture platform. This means that it has been designed to operate in tight integration with F5’s broad product portfolio, as well as support solutions from other leading virtualization companies such as VMware.
Explain the advantages of dedicated hardware (SSL card, compression card)
HARDWARE ACCELERATION REDUCES COSTS, INCREASES EFFICIENCY
SSL offloading relieves a Web server of the processing burden of encrypting and/or decrypting traffic sent via SSL, the security protocol that is implemented in every Web browser. The processing is offloaded to a separate device designed specifically to perform SSL acceleration or SSL termination.
SSL termination capability is particularly useful when used in conjunction with clusters of SSL VPNs, because it greatly increases the number of connections a cluster can handle.
BIG-IP® Local Traffic Manager with the SSL Acceleration Feature Module performs SSL offloading.

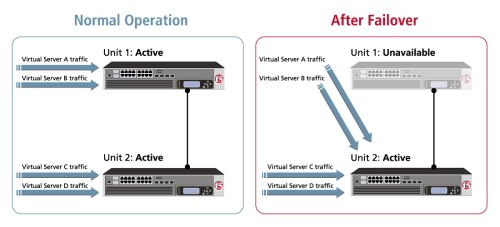
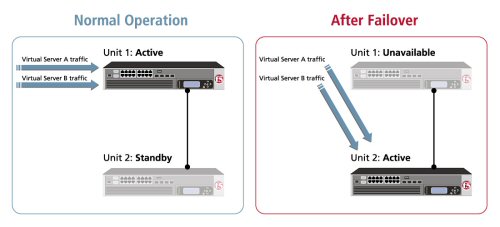


 THE FULL-PROXY DATA CENTER ARCHITECTURE
THE FULL-PROXY DATA CENTER ARCHITECTURE